Leveraging asynchronous hardware accelerators for fun and profit
One of the greatest benefits of Persistent Memory is that it’s directly accessible by the CPU. But that can also be one of its downsides for specific use cases. For example, if you want to use PMem as an ultra-fast storage device with low access latency.
PMem as storage impedance mismatch
The reason for that is simple - block storage I/O is typically asynchronous due
to its relatively high latency and high queue depths required to reach optimal
throughputs. This led to developers optimizing software for concurrent access to
the storage devices, either directly through asynchronous APIs like
io_uring or indirectly by relying on kernel’s built-in mechanisms such as
page caching or buffering. And now enter Persistent Memory, where the most
natural way of accessing it is synchronously with the CPU. This creates a mismatch
in storage use cases between what the software expects, an offloaded
background I/O operation, and what is actually happening, a synchronous memory copy.
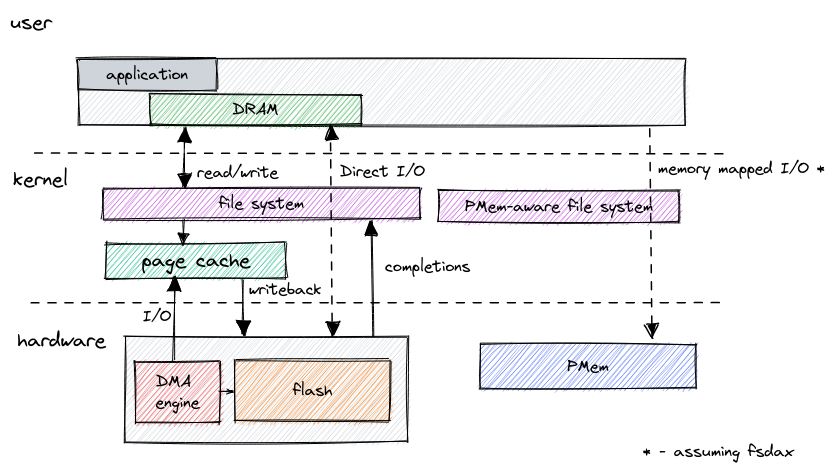
This mismatch manifests itself in the form of increased CPU usage when using PMem as a block device. So you might be getting higher throughput and lower latency in benchmarks but at the cost of increased CPU utilization.
Now, you can certainly optimize software by changing it to use a more memory-centric approach to Persistent Memory. But that’s a lot of work. And sometimes, asynchronous approach memory transfers simply make more sense, like in the case of bulk data operations.
Thankfully, starting in the next-generation Xeon (Sapphire Rapids), the platform will gain the ability to offload some of its memory operations through the use of a built-in DMA engine - Intel® Data Streaming Accelerator (Intel DSA).
Data Streaming Accelerator
DSA enables user-space software to quickly and efficiently perform a background
memory operation. Among supported operations are memory move (aka memcpy),
memory fill (aka memset) , cache flush, and memory compare (aka memcmp).
The DSA specification contains the full list.
This accelerator essentially makes it feasible for software to offload even
small memory operations from the CPU.
To use DSA, the system needs to configure groups composed of
work queues and execution engines. Work queues can be shared between
multiple users or dedicated to exclusive use by a single one. Once configured,
applications can access each work queue by mapping a special character device
exposed by the kernel. This map can then be used to directly submit work using
specialized instructions, MOVDIR64B or ENQCMD/S. Work submission and handling
can be done entirely from user-space.
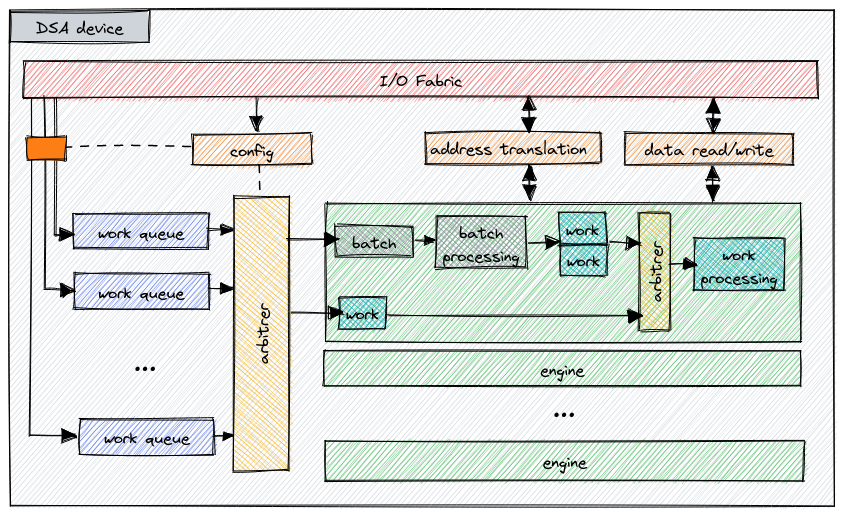
On completion of each work item, the hardware will store a completion record into a designated address. Software can also optionally request a completion interrupt, but user-space applications will need to carefully weigh the costs of using such an approach, especially in the case of small transfers.
To optimize busy polling on completion records, new CPUs will provide additional instructions that will allow applications to implement low power waiting schemes, potentially improving overall performance of the system.
Ultimately, DSA bridges the gap between the capabilities of traditional storage devices and Persistent Memory (and memory in general) by enabling asynchronous data movement. But it also goes beyond existing use cases like block storage, potentially facilitating new approaches to memory-related algorithms in databases, garbage collection, and other similar areas.
Data Mover Library
Using DSA directly can be quite involved. But most developers won’t need to program to raw device interfaces. Instead, they will be able to leverage libraries that provide convenient and easy-to-use APIs to asynchronous data movement. One such solution is Data Mover Library (DML).
void *
do_async_memcpy(void *dst, void *src, size_t n, useful_work_fn useful_work)
{
dml_status_t status;
uint32_t job_size;
/* initialize the job structure */
status = dml_get_job_size(path, &job_size);
assert(status == DML_STATUS_OK); /* error handling omitted for brevity */
/* jobs can be variably sized, so some form of dynamic allocation is required */
dml_job_t *dml_job = (dml_job_t *)malloc(vdm_dml->membuf, job_size);
assert(dml_job != NULL);
/* there are two job execution paths: DSA hardware and software fallback */
status = dml_init_job(DML_PATH_HW, dml_job);
assert(status == DML_STATUS_OK);
/* setup all the required parameters */
dml_job->operation = DML_OP_MEM_MOVE;
dml_job->source_first_ptr = (uint8_t *)src;
dml_job->destination_first_ptr = (uint8_t *)dest;
dml_job->source_length = n;
dml_job->destination_length = n;
dml_job->flags = DML_FLAG_COPY_ONLY;
/* and then submit the job to the work queue */
status = dml_submit_job(dml_job);
assert(status == DML_STATUS_OK);
/* now we can either wait or do something else and check completion later */
if (useful_work != NULL) {
do {
/* ...doing some useful work... */
useful_work(...);
} (dml_check_job(dml_job) != DML_STATUS_OK);
} else {
/* if there's nothing else to do, let's wait */
status = dml_wait_job(dml_job);
assert(status == DML_STATUS_OK);
}
return dst;
}
A C++ version is also available. See the DML github page for details.
The above code snippet sets up a job that will perform a memory move operation
in the background, allowing the CPU to do something else while the copy is
taking place. Admittedly, this is not as simple as just memcpy, but it does
provide more powerful asynchronous semantics.
The async ecosystem
Programmers are used to dealing with asynchronous I/O devices. Be it
block storage like described at the beginning of this article or
network interfaces. APIs like epoll, or lately io_uring,
have enabled developers to create highly efficient systems that minimize waiting
time and allow many tasks to be performed concurrently by one or more threads.
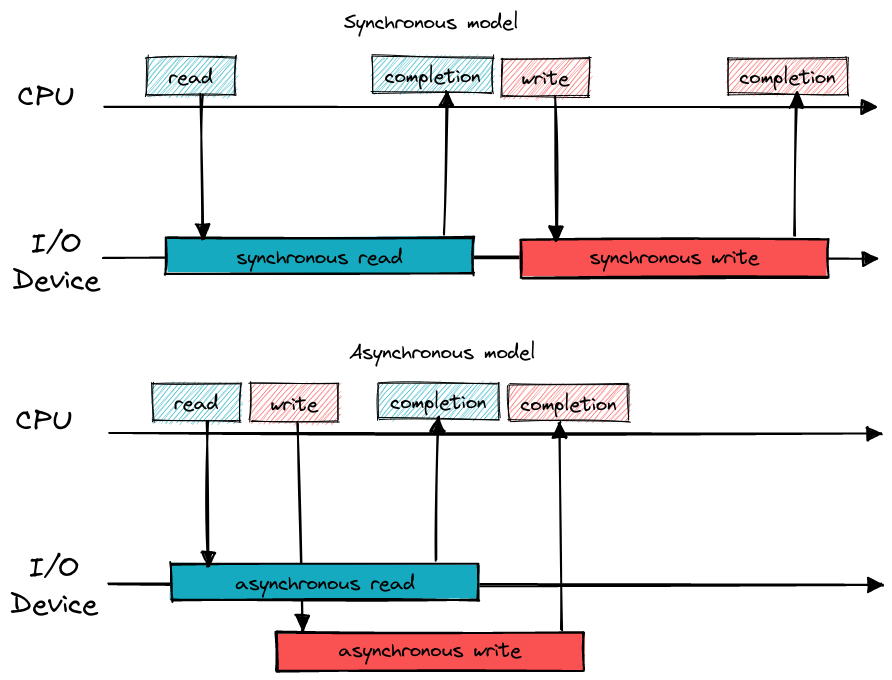
Programming languages are also increasingly capable of natively expressing
asynchronous semantics. High-level languages started this trend, but lower-level
ones such as C++, with coroutines,
and Rust, with async/await, are following suit.
task
async_useful_work(executor_type &executor)
{
/* perform some useful compute work */
}
task
async_memcpy(executor_type &executor, char *dst, char *src, size_t n)
{
/* perform an asynchronous memory copy using DSA */
}
task
do_copy_and_useful_work(executor_type &executor, char *dst, char *src, size_t n)
{
/* and now we can easily compose those operations using C++20 coroutines */
auto copy = async_memcpy(executor, dst, src, n);
auto work = async_useful_work(executor);
co_await when_all(copy, work); /* wait for async work to finish */
std::cout << "done" << std::endl;
}
As you can see from the example above, the new asynchronous semantics in C++20 provide a composable abstraction for concurrent work that is well suited for the new DSA hardware capabilities.
These modern approaches enable programmers to create readable and efficient programs that take advantage of background processing. And they also allow library developers to expose complex asynchronous tasks that can be executed concurrently, without breaking up functions into multiple smaller ones or relying on callbacks.
But… what about C?
The C programming language doesn’t have first-class support for asynchronous semantics, nor does it have a single widely used concurrency framework. Yes, there are frameworks such as argobots and popular libraries like libevent or libuv. Heck, there are even solutions that use the dark magics to provide coroutines in C. But while excellent at what they do, they all have their idiosyncrasies that make them mostly incompatible with each other.
Applications can directly use DML C APIs where appropriate, as I’ve shown earlier. But libraries that want to expose asynchronous functions have it more difficult. It’s hard to create higher-level functions that compose regular host CPU code and DSA operations.
And so when we first started thinking about introducing asynchronous operations in the various libraries in Persistent Memory Development Kit (PMDK), beyond just an async memcpy implementation, we found ourselves in a precarious position. We didn’t want for whatever we come up with to be tied to one particular framework, and we also wanted to avoid implementing our own highly-elaborate concurrency solution.
What we ended up creating is somewhere in between - libminiasync.
libminiasync
Our goal was to provide an easy-to-use and flexible mechanism for applications and libraries to compose and run higher-level asynchronous tasks. We also needed to ensure that our solution was platform-agnostic and usable in software that already uses an existing concurrency framework. Interoperability with other languages was also an objective - the C++ example I’ve included above was originally implemented using miniasync.
And no relying on dark arts :)
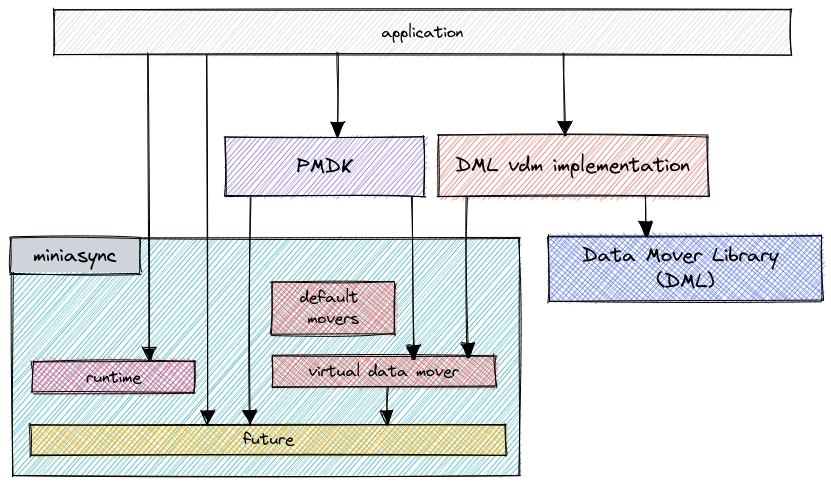
Our new library, libminiasync, accomplishes those goals by providing a minimal
abstraction of a future that represents an asynchronous task. At its core,
it’s simply a function (polling method) with some associated state and
the ability to chain the execution of those functions into larger futures. So it’s nothing
particularly inventive, but it’s relatively straightforward and has almost no overhead.
Futures that implement the miniasync’s abstraction can also be used with almost
any other concurrency framework.
/* define a future with a chain of other futures */
struct memcpy_then_useful_work_data {
FUTURE_CHAIN_ENTRY(struct vdm_operation_fut, memcpy);
FUTURE_CHAIN_ENTRY(struct async_useful_work, work);
};
struct memcpy_then_useful_work_output {
...
};
/* a helper macros that creates all the relevant data structures for the future */
FUTURE(memcpy_then_useful_work_fut, struct memcpy_then_useful_work_data,
struct memcpy_and_useful_work_output);
/* the function that puts it all together to instantiate a future */
static struct memcpy_then_useful_work_fut
async_memcpy_then_useful_work(struct vdm *vdm, void *dest, void *src, size_t n)
{
struct memcpy_then_useful_work_fut chain = {0};
FUTURE_CHAIN_ENTRY_INIT(&chain.data.memcpy,
vdm_memcpy(vdm, dest, src, n, 0),
memcpy_to_work_map, NULL);
FUTURE_CHAIN_ENTRY_INIT(&chain.data.work, async_work(), NULL, NULL);
FUTURE_CHAIN_INIT(&chain);
return chain;
}
...
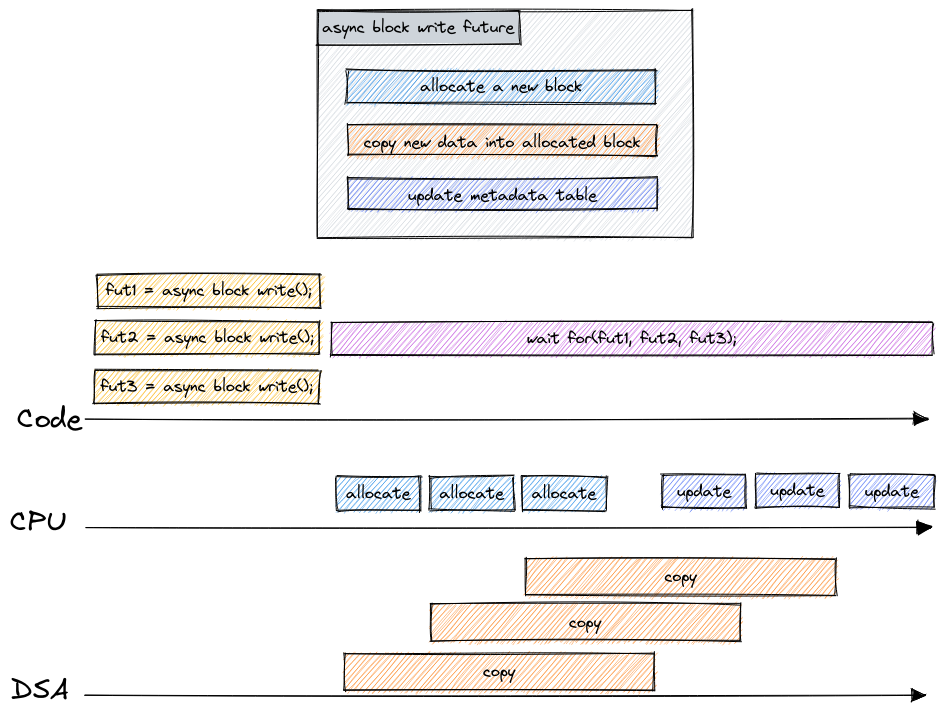
/* the user is left with a fairly easy to use interface to concurrently run the futures */
struct async_memcpy_then_useful_work_fut task;
task = async_memcpy_then_useful_work(dml_mover, buf_b, buf_a, testbuf_size);
/* manually drive the task to completion using its poll method */
while (future_poll(FUTURE_AS_RUNNABLE(&task), NULL) != FUTURE_STATE_COMPLETE) {
/* pause... */
}
Based on the ‘basic’ miniasync example.
Defining a future requires some boilerplate, but once that’s done, its use is straightforward. Software can just instantiate the future and execute it. We feel that this is an acceptable tradeoff, given that the tricky bits will be left mostly for library developers to deal with.
The miniasync library will also ship with two additional components. A rudimentary runtime that facilitates concurrent execution of futures and a virtual data mover that provides an abstraction for asynchronous memory operations.
Async runtime
The core miniasync abstraction is intentionally very barebones. This enables software to make its own decisions regarding the execution and scheduling of futures. Some applications might need complex job-stealing scheduling runtimes, whereas some will be satisfied with simpler single-threaded ones. Existing software might want to rely on an execution system that it already uses (e.g., an SPDK reactor). Miniasync supports all these use cases. However, we didn’t want to leave it at that and not provide any runtime whatsoever. That’s why miniasync will initially ship with a simple single-threaded runtime that supports concurrent execution of futures.
struct async_memcpy_and_useful_work_fut tasks[2];
tasks[0] = async_memcpy_then_useful_work(dml_mover, buf_b, buf_a, testbuf_size);
tasks[1] = async_memcpy_then_useful_work(dml_mover, buf_b, buf_a, testbuf_size);
/* this drives both futures to completion using the runtime */
runtime_wait_all(runtime, (struct future *)tasks, 2);
We are also thinking about creating a multi-threaded runtime that would distribute the futures across multiple threads. Reach out if you’d like to see that.
Virtual Data Movers
The primary thing that we are enabling with all this effort is the use of DSA in the PMDK libraries. So as part of miniasync, we are also implementing a virtual data mover (vdm) abstraction.
/* instantiate a new concrete data mover based on DML */
struct data_mover_dml *dmd = data_mover_dml_new();
assert(dmd != NULL);
struct vdm *mover = data_mover_dml_get_vdm(dmd);
struct vdm_operation_future a_to_b =
vdm_memcpy(mover, buf_b, buf_a, buf_size, 0);
runtime_wait(r, FUTURE_AS_RUNNABLE(&a_to_b));
The purpose of the vdm is to provide a common interface for asynchronous memory operations. Software can then be written once using the vdm abstraction but, at runtime, choose between various implementations based on its needs and the platform capabilities. For example, an application that uses SPDK and runs on an Intel platform might want to use an SPDK-based DSA implementation, whereas a generic multi-platform application might want to dynamically choose between a software fallback or a hardware-specific accelerator (e.g., DSA through DML).
More to come
The libminiasync software I’ve described above is still a work in progress. If you are interested in learning more, please see miniasync’s github page. We’d also love to hear any feedback about our efforts, so don’t hesitate to reach out.
In the following article, coming soon, we will describe how miniasync integrates with libpmem2 and the plans for integration with the rest of PMDK. We will also circle back to the block storage on PMem problem that I started with by exploring an example implementation of asynchronous pmemblk operations.