Upcoming asynchronous interfaces in PMDK libraries
In the previous article, I wrote about a new upcoming Xeon platform feature, Data Streaming Accelerator (DSA) - a memory-to-memory DMA engine, and what opportunities and challenges it presents. I outlined the approach we are taking in Persistent Memory Development Kit (PMDK) to expose asynchronous APIs that can take advantage of this new hardware. Lastly, I introduced libminiasync, which is our framework for abstracting asynchronous operations.
This time, I will discuss how miniasync is being used in libpmem2 and our plans for its integration into the rest of PMDK libraries.
Technical considerations for supporting new hardware or OS features in PMDK
PMDK is a sizable collection of existing tools and libraries. It supports various different architectures (x86-64, aarch64, ppc64, riscv64) and systems (Linux, Windows, FreeBSD). Introducing support for any new hardware or OS features requires careful deliberation to ensure our software remains usable for our existing users, no matter the platform they are using or the upgrade path they are taking. We also need to make sure that any software abstractions for hardware features we introduce aren’t tied to any particular implementation. This is especially important for any public interfaces since they are hard to change after release.
With DSA, we have the perfect storm - it’s both a new hardware feature and a capability that requires a fairly extensive public interface. We also cannot pick just one software implementation like DML to help us with our abstraction, since we already know that there are potential users that might wish to leverage an alternative software layer, like the one provided in SPDK.
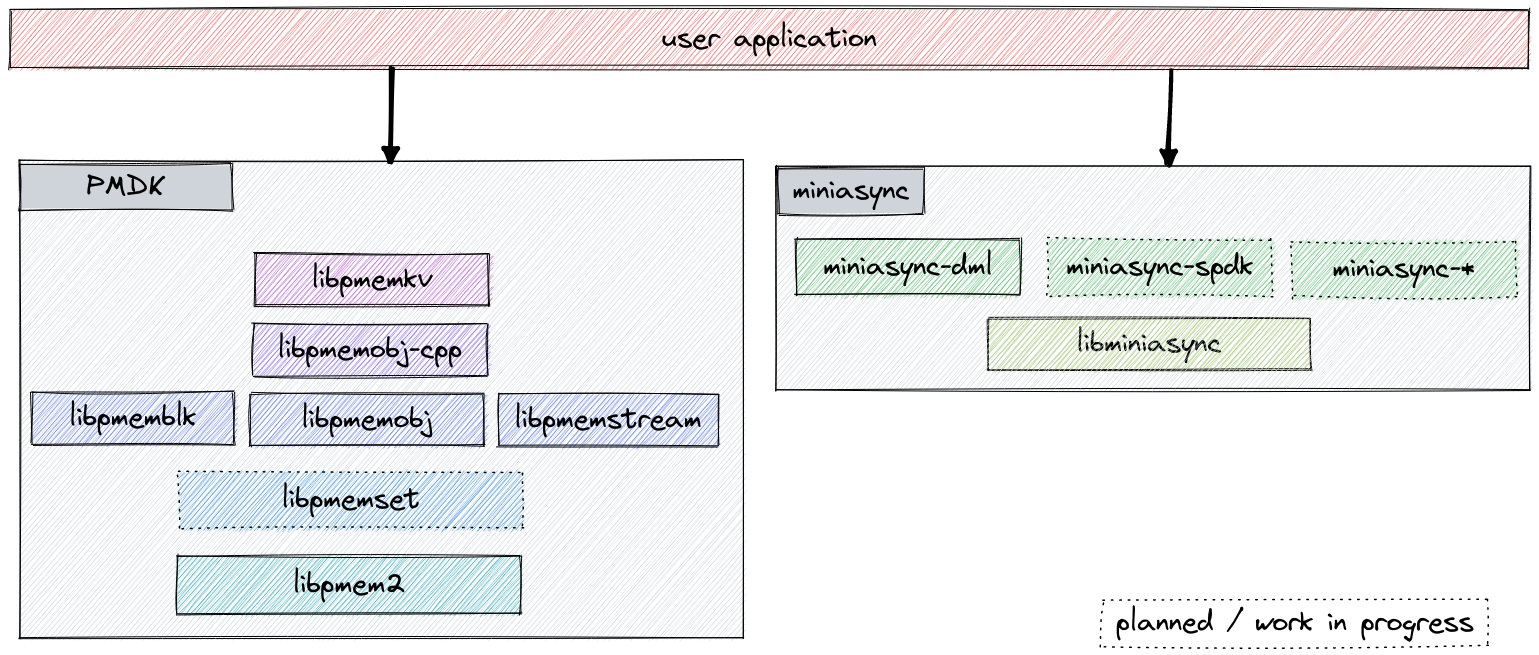
With all that in mind, we’ve created miniasync - a fairly generic abstraction for asynchronous operations. It allows us to create public APIs in PMDK libraries that operate purely on abstract asynchronous functions, with the actual data movement implementation provided at runtime by the user. Or not, in which case a software callback is used.
Integrating miniasync with pmem2
PMDK is a stack of libraries, one building on top of another. To create highly
elaborate async functionality in the highest layer of that stack, we first need
to enable everything below it, starting from the bottom - libpmem2. It is our
core library that provides the foundations for persistent memory programming. It
abstracts away the memory mapping and flushing primitives, implements
PMem-optimized memory operations like memcpy or memset, and provides
Reliability, Availability, and Serviceability (RAS) APIs.
As a starting point, we are adding asynchronous memcpy, memmove and memset
APIs to pmem2.
struct pmem2_future pmem2_memcpy_async(struct pmem2_map *map,
void *pmemdest, const void *src, size_t len, unsigned flags);
struct pmem2_future pmem2_memmove_async(struct pmem2_map *map,
void *pmemdest, const void *src, size_t len, unsigned flags);
struct pmem2_future pmem2_memset_async(struct pmem2_map *map,
void *str, int c, size_t n, unsigned flags);
These functions map the regular synchronous pmem2 primitives onto asynchronous futures provided by miniasync. But to actually use DSA, or a different asynchronous data movement engine, users will need to explicitly assign a virtual data mover (vdm) instance to the pmem2 map.
int pmem2_config_set_vdm(struct pmem2_config *cfg, struct vdm *vdm);
Without this, pmem2 will use a software fallback based on its implementation of memory operations.
To use these async functions, the software will need to define PMEM2_USE_MINIASYNC
prior to including pmem2.
#define PMEM2_USE_MINIASYNC 1
#include "libpmem2.h"
This is because we’ve made a conscious decision to make this software feature entirely optional, at least for now. We also made sure that the core miniasync abstractions (futures, vdm) are header-only. This will make it easier for existing users to upgrade PMDK version if they don’t want miniasync. It will also make it possible for us to package pmem2 into various linux and windows repositories without having first to package miniasync.
Future-looking plans and ideas
As I’ve said above, our work on asynchronous interfaces doesn’t stop with pmem2. We intend on leveraging miniasync throughout the stack of PMDK libraries. The first example of that is in pmemstream, our work-in-progress solution for efficient log storage and processing.
In pmemstream, we want to make a general abstraction for all types of logs. We also want to make sure that our library doesn’t just run on PMem, but also supports a wider variety of heterogeneous memory and storage systems. To accomplish that, we are designing our on-media layout in a way that seamlessly supports buffered durable linearizability. This means that we can make writes fully asynchronous while still making sure that everything remains consistent, even in the presence of failures. And obviously we are going to use miniasync to create that asynchronous API.
Our other plans include using asynchronous APIs in libpmemobj, our transactional object storage system. One of the enhancements that we are thinking about is improving our undo and redo logging implementations to allow concurrent processing of log entries, potentially reducing the time it takes for transactions to be committed or aborted.
And, of course, we also want to use miniasync in our user-space block storage API - libpmemblk.
Asynchronous block storage APIs
The pmemblk library is a failure-atomic implementation of a block storage interface on top of Persistent Memory. This is needed because PMem, unlike standard enterprise disks, does not provide sector atomicity (because there are no sectors). If you were to simply create a huge array of blocks and write to it directly, you might have data consistency issues when the system crashes. This behavior might be fine for software designed to tolerate failures, but not for anything else. Our library addresses this problem through the use of Block Translation Table algorithm.
However, as I’ve described in my first article, using PMem as block storage has an additional cost of using the CPU to perform the actual I/O. This also applies to libpmemblk. Thankfully, with DSA and miniasync, we can address this problem.
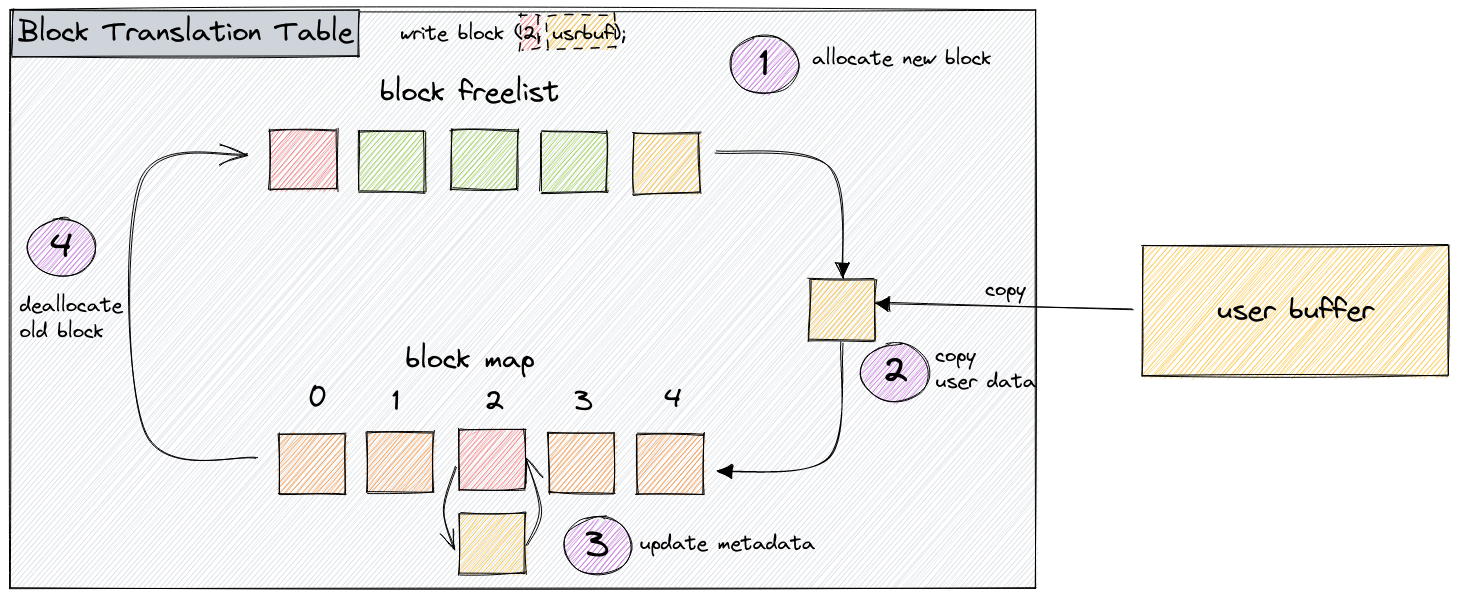
Logically, a write in the BTT algorithm I mentioned earlier is composed of four steps:
- Allocate a new block for the new write.
- Perform a memory copy to populate the newly allocated block.
- Update metadata, pointing it to the new block.
- Deallocate the previous block for that position.
To make the API thread-safe, the implementation protects these steps with a myriad of locks and other concurrency mechanisms.
Out of these four operations, we want to leverage DSA for the second step, the memory copy of the data itself. We could do this transparently by simply replacing memcpy with an async version. But that wouldn’t really allow for concurrency. We need to break-up these steps into individual futures, so that users can run multiple concurrent block write operations even from a single thread. Thanks to the miniasync framework, that in itself is not much of a problem. But we do have to be careful around existing concurrency primitives and operating system locks - this is because holding a lock across a future boundary might lead to deadlocks, where a single thread tries to acquire the same lock twice, but in separate async operations.
Summary
In this blog series, I’ve described the PMDK team’s efforts to enable DSA in existing and upcoming libraries. All this work is happening on our github. If you are interested, please take a look around and let us know what you think. Any feedback we receive from our users is very valuable to us.