300 nanoseconds (2 of 2)
At the end of the first part of this blog series, I posed three fundamental questions regarding the design of failure atomic data structures for persistent memory.
- What does it mean to allocate persistent memory?
- How to do fail-safe atomic updates?
- Are all data structures suitable for persistent memory?
This time around, I will try to answer these questions to the best of my ability. We will return to the doubly-linked list example to see how it can be modified for PMEM. Finally, I will briefly discuss the evolution of libpmemobj as we refined its internal algorithms for the best performance.
Dynamic memory allocation of Persistent Memory
Let’s imagine we are just starting to create our very first persistent memory program, a simple note-taking application. Since PMEM is exposed by the operating system using files, our first step has to include opening and memory mapping one. That gives us a pointer to N bytes of contiguous virtual address space which directly represents the underlying persistent memory. Yay!
Now what?
We could simply lay out everything statically in memory, limiting the functionality of our application - with this approach the size and the number of notes we could take would be predefined.
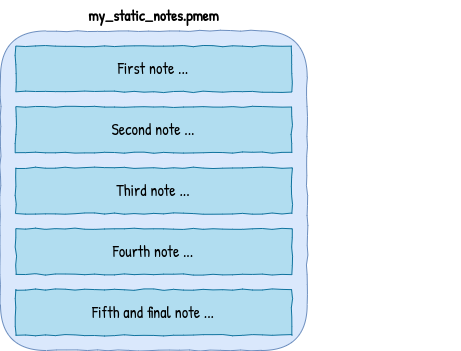
But we are more ambitious than that, we want to dynamically manage the number of notes and how big they are. We need something that will manage our region of memory and keep track of which bytes already contain a note and which don’t. That something is usually referred to as memory allocator or, less commonly, a heap manager.
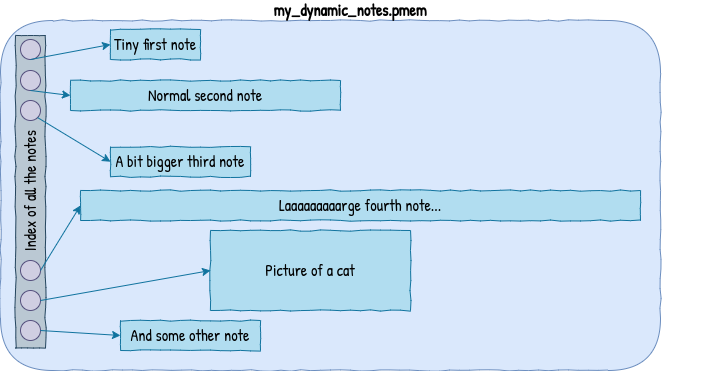
The two most important properties of traditional memory allocators are:
- Time efficiency - the number of cycles it takes to perform an allocation.
- Space efficiency - the size and amount of gaps in-between allocated memory blocks.
There are many ways of accomplishing those goals. We describe a couple in Chapter 16 of the Programming Persistent Memory book. In this post, we are going to focus on two properties important for a persistent memory allocator, namely correctness and failure safety.
Our note-taking app wouldn’t be very useful if there were no way of reconnecting back to the existing file after restarting the application. And so, when implementing an allocator the heap layout needs to be laid out in a way that allows for a quick rediscovery of available free memory blocks.
One way of accomplishing that is to implement all tracking data structures directly on persistent memory. For complex allocators, it usually means a couple of different dynamic ordered and unordered containers. For scalable allocators, we’d also need a way to divide memory areas between different threads which efficiently redistributes free space after a restart.
I’ve spent many weeks tilting at that particular windmill…
While this approach of “simply” making everything persistent is certainly doable, it quickly becomes complex and just… slow. PMEM has higher access latency, and on top of that, we can’t forget about fail-safety. Allocators also tend to frequently re-use the same memory locations with the goal of increasing the chance of cache hits. Well, if you have to evict the memory from the cache after a store to make it persistent, it’s a recipe for a guaranteed cache-miss.
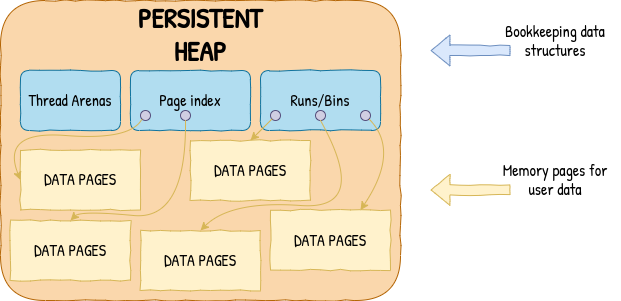
So, what can we do instead? We can learn a lesson from how file systems solve similar problems. We can design our on-media layout such that all the metadata is compact and quick to iterate over and have separate runtime-only data structures that are used to manage the persistent state. This enables the heap recovery process to still be nearly instantaneous, while significantly improving runtime performance. In libpmemobj, the allocator only needs to look at about 256 kilobytes of metadata for every 16 gigabytes of memory to rebuild all the necessary data structures and it does so lazily, which further reduces the recovery time.
Coincidentally, separating runtime bookkeeping from the persistent state is also beneficial for fail-safety. We can now retrieve a free block from the runtime state, populate it with data, and only then perform the persistent state changes that mark the block as allocated. This is how libpmemobj now maintains the fail-safety of memory allocations within a transaction. Transactional allocation only retrieves a free block from the runtime data structures, and only while the transaction is being committed, the persistent state is updated. Turns out this is both faster and simpler to implement than the alternative.
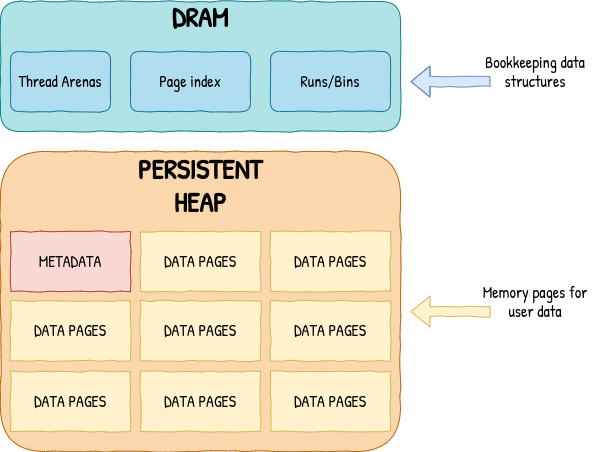
Going back to the note-taking application, the described approach enables us to first reserve a new note, write something in it, and only once it is complete, make it persistently allocated and reachable.
Fail-safe atomic updates
A fail-safe memory allocator is only a piece of the puzzle. We also need to consider how to update existing memory locations in a way that the assumptions about the application’s data structures hold even in the presence of failures.
To visualize the problem, let’s look at the linked list again:

This data structure is consistent only if all of the following conditions are met:
- The first node’s
prevpointer isNULLor a sentinel object. - The last node’s
nextpointer isNULLor a sentinel object. - For every two nodes
AandB, ifA->nextpoints toB, thenB->prevmust be pointing toA.
While the first two conditions can be met without much of an issue, the last condition requires that the modification of multiple variables must be atomic. Like we discussed previously if this were about concurrency, we’d protect the insert operation of the linked list with a lock. But that’s not the type of atomicity we are after. We need this operation to be failure atomic, meaning that the conditions we’ve outlined need to still be true even in the presence of failures.
There are two common solutions to this problem, redo and undo logging. Each with different performance and usability tradeoffs. To illustrate how these two types of logs work, we will go over how a fail-safe insert to a linked list can be implemented using both redo and undo logs.
But before we do that, let’s take a look at the steps required for a failure atomic linked list insert.
- A new object must be allocated and populated with data, which includes the
nextandprevpointers. - The
nextpointer of the predecessor node must be updated with the address of the new object. - The
prevpointer of the successor node must be updated with the address of the new object.
While the pointer updates are self-explanatory, the allocation must also happen alongside all other changes. This is where the allocator design I’ve described in the previous section comes into play. In optimized implementations, the insert operation can first reserve the new object, fill it, and update the persistent state for the allocation alongside other changes in the log.
For the sake of simplicity, in the diagrams below I use the terms alloc() and free() to
indicate what happens to the new object. For the described design, this means “update
the persistent metadata to match the new state of the object”.
With that out of the way, let’s finally take a look at the redo log.
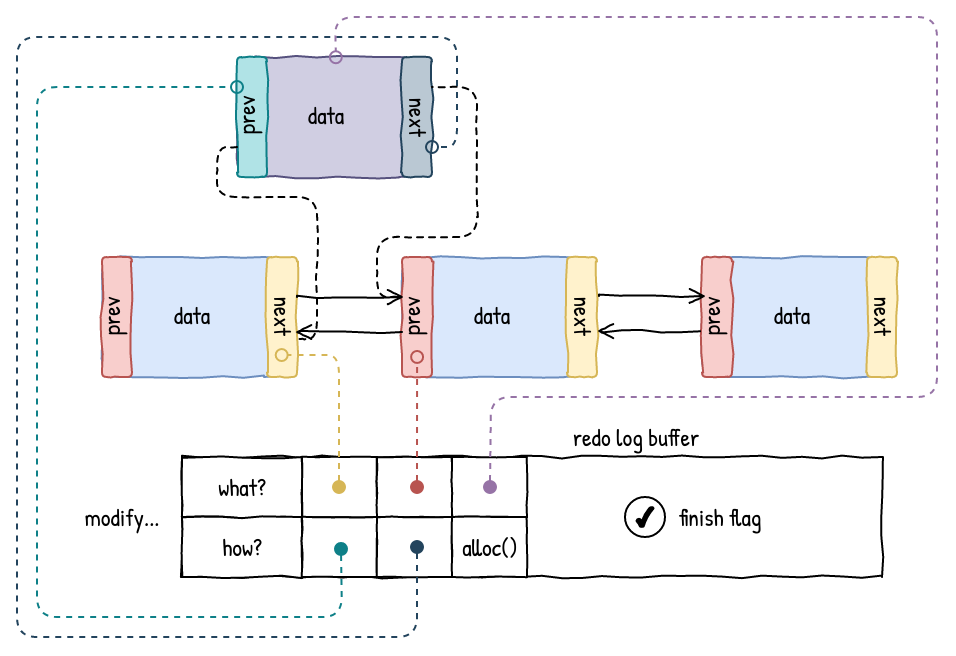
With the redo approach, the data to be modified is stored in the log prior to any changes on the objects in the data structure. Only when all of the changes are staged in the log, and some sort of a finish flag is set, the log is processed and all the changes are applied. If this process were to be interrupted for whatever reason, it can be simply repeated until successful and the finish flag is cleared.
The obvious consequence of using a redo log is that changes to data structures are not immediately visible. This might be both a good or a bad thing, depending on how you look at it. For example, this behavior plays better with a multi-threaded code where the goal is to hide partial state changes anyway.
But what about performance? Well, in our experience with libpmemobj, redo logs are a natural fit for buffering in a faster medium (DRAM) before being written out sequentially to a slower one (PMEM). Writing and flushing one bigger buffer instead of three smaller ones, like in our linked list example, is obviously faster.
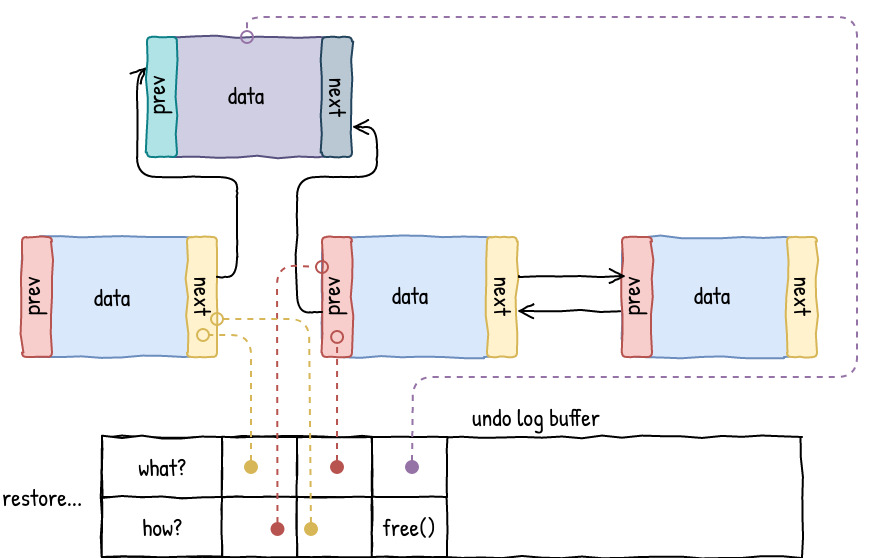
Undo log is similar, but instead of creating logs of the new data, it creates snapshots of the memory regions just prior to modification. If the transaction is aborted halfway through, the log will be used to rollback any changes that might have been done to the data structure. In some implementations, such undo log would also have to deallocate any objects that were created as part of the transaction. And that’s precisely what libpmemobj did in old versions (before 1.4). We’ve since optimized this path so that no persistent metadata is modified as part of transactional allocation, and objects are only marked as allocated during the transaction’s commit.
Undo logs are useful because they enable immediate visibility of changes to memory, which just happens to be exactly what normal programming model with loads and stores provides. All we have to do to modify an existing application is to add instrumentation before all modifications and things generally just work.
However, using undo logs this way has performance implications. The more individual synchronous transfers have to be done, the larger the overall overhead for the transaction. This is the reason why we have added redo-log based APIs and simple undo log batching to libpmemobj.
We’ve now learned how to create a failure atomic doubly linked list. Now all that remains is to ask ourselves if that’s even a good idea to begin with. And yes, I realize the order of these actions is a little backward, but it’s the order in which we did it, so… :)
Failure Atomic Data Structures
The feasibility of a data structure is ultimately determined by its usability and performance for a given use case. In libpmemobj we initially used intrusive doubly linked lists to store individual transaction log entries. While this had its benefits, like relative design simplicity (the implementation was anything but simple), its task was better served by specialized buffer log data structure that we were able to implement with almost 0 cache-misses in the write path. The performance improvements shown in the previous post can be in large parts attributed to the continued refinement of this log data structure.
But that’s only one use case, what about everything else? In my opinion the two most important things to look for in a potential failure atomic data structure are a) the amount of non-contiguous small writes it does and b) a cache friendly access pattern.
For example, a vector is a better failure atomic data structure compared to a linked list, because its insert operation is very simple and it doesn’t do any pointer chasing during iteration. This might seem obvious, but I think it’s still worth saying. There are some scenarios where a list is necessary, but more often than not there’s a way around it that can use a vector or something with similar characteristics.
A little less obvious example are binary trees. While a regular B-Tree can still be considered a good data structure for Persistent Memory, it does have a fairly complex insert (and remove) operation that needs to be heavily optimized to avoid excessive transaction overhead. The same is true for red-black or AVL trees, which, from our experiments, perform poorly when made to be failure atomic. This is mostly due to the considerable depth of the trees and complex insert/remove operations. We found that better failure atomic ordered data structures are height optimized compact tries, such as ART or HOT. The reason for this is because they allow for densely packed nodes and have trivial insert operations.
As for hash tables, the same general ideas apply. Separate chaining will increase the number of cache misses and is likely to have a more write intensive insert and remove operations. In our experiments, open addressing schemes such as simple linear probing or Robin Hood hashing perform fairly well.
It’s also possible to combine both PMEM and DRAM to achieve higher performance. This approach can be successfully employed with careful coding and consideration for pros and cons - you wouldn’t want to wait hours for your index to rebuild, would you? But that’s a topic for a different post.
Summary
Throughout this short series, I have discussed the various challenges associated with writing high performance code for Persistent Memory. I also covered different approaches to tackling those challenges based on my experience with libpmemobj’s implementation. And finally, I briefly shared my thoughts on failure atomic data structure design.
Thanks for sticking with me, I hope this was interesting :)