Disaggregated Memory - In pursuit of scale and efficiency
A software person perspective on new upcoming interconnect technologies.
Existing Server Landscape
Servers are expensive. And difficult to maintain properly. That’s why most people turn to the public cloud for their hosting and computing needs. Dynamic virtual server instances have been key to unlocking efficiency gains for both Cloud Service Providers (CSPs) and their users. CSPs can leverage virtualization to colocate many workloads on fewer physical servers. And cloud users have access to a huge pool of on-demand processing power, only having to pay for what they use. It’s a win-win scenario in terms of efficiency. More people share fewer resources.
However, there are still many resources that are not utilized as efficiently as they could be. Most pertinently, memory. And memory is pricey; it’s often the single most expensive component in a typical server. Also, DRAM technology scaling is increasingly challenging [1], which, combined with the rapidly increasing number of cores in modern processors, means that it’s increasingly difficult for CSPs and hardware vendors to provide sufficient memory capacity and bandwidth per CPU core. And there are only so many memory channels you can add to a server before you physically run out of space on the motherboard.
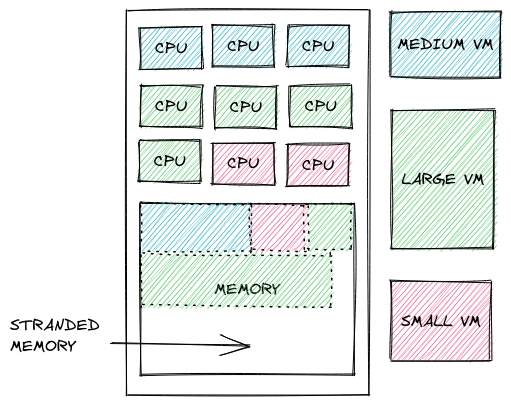
On top of all that, we are likely not utilizing existing memory capacity as efficiently as we could. “Google, Facebook, and Alibaba report that as much as 50% of server memory in data centers is unutilized” [2]. Some of that memory is left unallocated at a hypervisor level. Some is stranded because all local cores are already allocated. Some is also left unused at the application/OS level. At cloud scale, that’s literally billions of dollars in hardware sitting idle.
Scaling memory
So, how can we continue scaling memory capacity and bandwidth while keeping costs under control? By moving most of the memory outside of the server. This has already happened, to an extent, with block storage. Cloud storage services, such as Amazon’s Simple Storage Service (S3), let servers access remote data, making individual instances essentially ephemeral and interchangeable. But they also allow CSPs to pool resources and enable their customers to dynamically scale their storage needs over time. And yes, there’s some cost to it. Remote storage is not as fast as a local NVMe drive can be. But, based on the popularity of cloud storage solutions, horizontal scalability benefits clearly outweigh the costs of reduced vertical scaling. For many, locally attached storage has become a cache.
So, M3 (Magnificent Memory Manager?) anyone? But is moving memory outside of the server even possible? Many people in the industry and academia considered approaches that use regular network hardware. Remote Direct Memory Access (RDMA) technologies, such as Infiniband, can be leveraged to create approximate solutions to disaggregated memory with fairly low latency. But not memory-like latency. So we end up with swap-style implementations (e.g., INFINISWAP [3]), and not true remote attached memory. But if RDMA isn’t the answer, then what is? Modern high-speed cache-coherent interconnects with memory pooling.
CXL
An example of such technology is CXL [4]. It’s an interconnect standard built on top of PCIe. It has many features, but, most notably for this discussion, CXL facilitates cache-coherent memory access between CPUs and supporting PCIe-attached devices (pure memory devices but also accelerators). This is called CXL.cache and CXL.mem. The 2.0 version of the standard additionally enables a single CXL device to connect to multiple hosts.
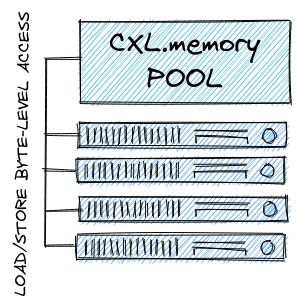
CXL-attached memory, given that it uses PCIe, also has the added benefit of being easier to manage (e.g., hot-plugged memory) and easier to scale (both in terms of capacity and bandwidth) than DDR memory in a DIMM form-factor. And, speaking of form factors, many hardware vendors have already announced plans [5] to use EDSFF (Enterprise & Data Center SSD Form Factor) together with CXL. So it’s likely that in the future we will see servers where both memory and storage (among other things) go into exactly the same slot. So convenient.
Memory Disaggregation
CXL, in essence, lets infrastructure providers build scalable systems with rack-level disaggregated on-demand memory, increasing allocation flexibility. This should allow cloud users to downscale their initial memory provision and then dynamically allocate and deallocate memory pages based on application demand.
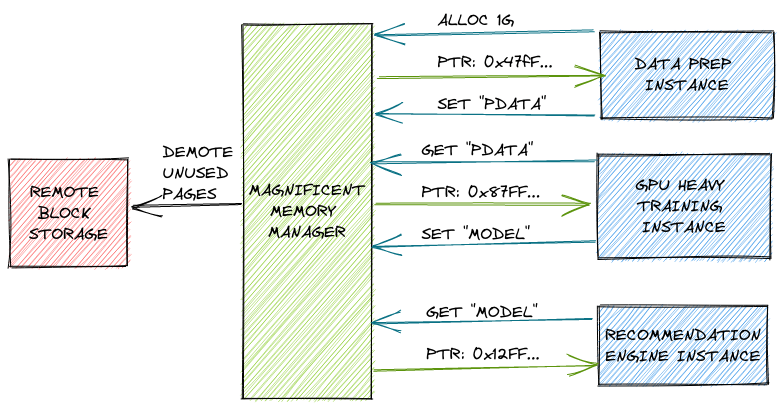
What’s also possible are cloud memory services where applications connect to named remote memory regions that preserve their content. So just like cloud block storage, but with bytes. Such capability might unleash programmers to do all sorts of crazy optimizations - from dramatically reducing startup time, through eliminating serialization/deserialization costs in multi-step processes to storing database indexes purely in shared distributed memory. And what’s really cool is that those named memory regions wouldn’t even have to reside in rack-level memory pool while unused. They can be paged out to slower block storage. This is all hypothetical at this point, but the possibilities are endless. We will see what happens once the hardware hits the market.
It’s not all roses and sunshine
But there’s always a but. In the case of cloud storage, it is latency. Unsurprisingly, that’s also the case for CXL.mem. Memory connected through this interconnect will not be as quick to access as ordinary DIMMs due to inherent protocol costs. Since this is all upcoming technology, no one has yet published an official benchmark that would allow us to quantify the difference. However, it’s expected that the difference will be similar to that of a local vs remote NUMA node access [6]. At least for CXL attached DRAM. That’s still plenty fast. But is it fast enough for applications not to notice if suddenly some of its memory accesses take twice (or more) as long? Only time will tell, but I’m not so sure. For the most part, software that isn’t NUMA-aware doesn’t really scale all that well across sockets.
Heterogeneous memory hierarchy
In practice, the CXL.mem protocol expands the increasingly heterogeneous memory hierarchy of modern servers. The specific access latency of remote attached memory will depend on the type of media used in the device. So it’s not impossible to imagine a scenario where there are three or even more memory types in a single system, all with different performance characteristics.
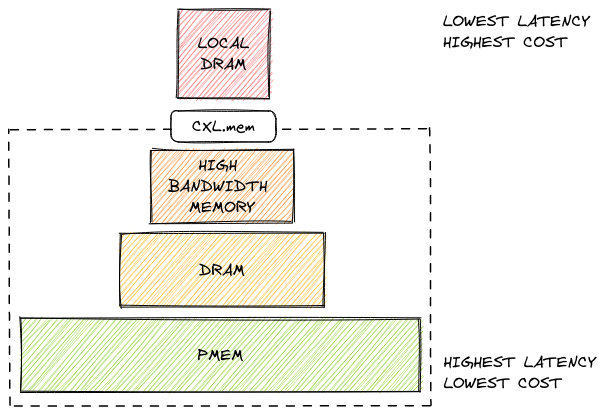
Given that there might be many different types of memory in a system, there naturally needs to be something that will let software identify the performance characteristics of those devices. Luckily, that something already exists. It’s called Heterogeneous Memory Attribute Table (HMAT), and it’s part of the ACPI spec. HMAT exposes information required to determine the performance characteristics (latency, bandwidth) of a memory device (target) as accessed from a CPU or other I/O device (initiator). Operating systems can parse that table and expose performance information [7] to user-space software.
If you’d like to learn more, we’ve described HMAT in the context of memkind in an earlier article [8] on pmem.io.
Implications for software
Armed with this knowledge, software should then be able to make informed data placement decisions about which allocations go to which memory. But how? And, better yet, why? Wouldn’t it be better for some lower-level abstraction to handle this transparently for applications?
And to the extent that transparent data placement is possible, I agree. But there are some caveats, in my opinion.
First, making decisions about data placement is mostly about predicting the
system’s future behavior. The lower in the stack we make those decisions,
the less information is available for predictions. And sure, cache
replacement policies aren’t anything new. It’s a well-researched topic. The critical
difference with memory is that data is directly accessible. It doesn’t
have to be moved to DRAM on access. So there are additional considerations to
make, such as promotion policies or observing data access patterns beyond simple
get(key) as with typical caching solutions.
Second, any genuinely transparent universal tiering solution would likely operate on pages. And pages are typically far larger than individual data objects. Especially nowadays, where memory capacities are increasing and using huge pages is often advisable to increase performance [9]. You wouldn’t want your OS constantly moving 2MB blocks between different memory tiers. Such transparent solutions, to work optimally, would have to be complemented by user-space software that considers the spatial locality of memory objects within a page during allocation (and probably beyond).
Ongoing software enabling efforts
Ultimately, I think the best solutions are likely to consist of a kernel-level (or hypervisor-level) mechanism for memory migration between tiers and an optimized user-space software component to ensure hot and cold data is stored on separate pages. Both working together to maximize performance. And both are already being worked on by many different people. There are now many Linux [10] kernel memory tiering [11] activities. And just as many user-space software projects trying to tackle page placement problems. Memkind among them.
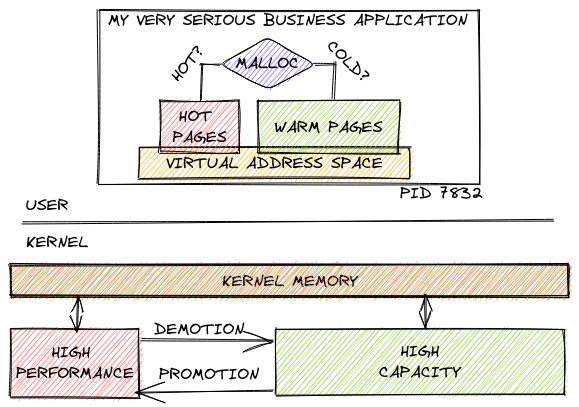
That sounds all good and fine for volatile memory, where we care only about additional capacity and efficiency gains. But what about those named memory regions I mentioned earlier? In that case, software will need to be modified so that it can attach to existing regions instead of just allocating new ones. It would also likely need some logic to make safe updates to such regions. I hope that Persistent Memory Development Kit (PMDK) can serve those needs when they inevitably (hopefully :)) show up.
And the master plan is revealed. Well, not really. But it’s nice when things start to align.
References
[1] Scaling and Performance Challenges of Future DRAM
[2] Redy: Remote Dynamic Memory Cache
[3] Efficient Memory Disaggregation with Infiniswap
[4] Compute Express Link™: The Breakthrough CPU-to-Device Interconnect
[5] KIOXIA Introducing the EDSFF E3 Family of Form Factors
[6] The CXL Roadmap Opens Up The Memory Hierarchy
[7] Linux kernel guide - NUMA Locality
[8] Memkind support for heterogeneous memory attributes
[9] Beyond malloc efficiency to fleet efficiency: a hugepage-aware memory allocator
[10] Optimize Page Placement in Tiered Memory System
[11] Migrate Pages in lieu of discard