Memkind support for heterogeneous memory attributes
Introduction
Memkind is a library mostly associated with enabling Persistent Memory. However, it is not the only type of memory that memkind supports. The library is a general solution designed for platforms with heterogeneous memory.
But before we delve into heterogeneous memory itself, let’s start with a short recap about NUMA. The NUMA concept solved the problem of a dynamic extension of the CPU count per socket and system memory. Before NUMA, Uniform Memory Access (UMA) was a common model, in which all processors shared physical memory uniformly. With the UMA approach and a rapid growth of a number of processors and memory in multi-socket machines, platforms faced scalability problems. A single shared bus connecting all CPU(s) and DRAM memory became a bottleneck, as each CPU decreased the available bandwidth. To handle each new device, the length of the bus had to be extended, which in turn negatively impacted the latency.
A new strategy was introduced: Non Uniform Memory Access(NUMA) as a solution to the challenges mentioned above.
Instead of providing a single shared bus, the concept proposed a solution to divide the hardware resources into NUMA Nodes abstraction.
Depending on the exact implementation on multi-socket platforms, NUMA Node could be exposed as CPU(s) and memory placed inside the same socket.
Accessing memory placed on the same socket as the CPU on which process runs (local memory access) was faster since it avoided
additional overhead from the interconnect, as in memory access between two sockets (remote memory access).
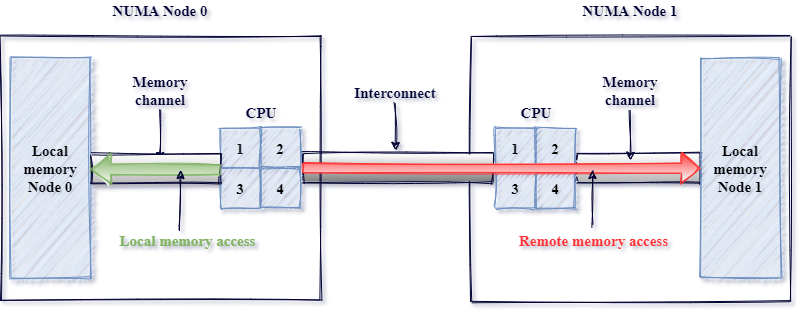
The Linux systems make a memory allocation decision, among other factors, based on NUMA distance. The distance represents
relative memory latency between NUMA nodes, and is based on hardware configuration - System Locality Information Table (SLIT) and
System Resource Affinity Table (SRAT) present in ACPI.
NUMA-aware Operating System can still consume all available memory, but the OS will optimize it for local memory access.
In practice, this means that memory allocation will come from the NUMA Node with the smallest distance from the CPU core
of the calling thread.
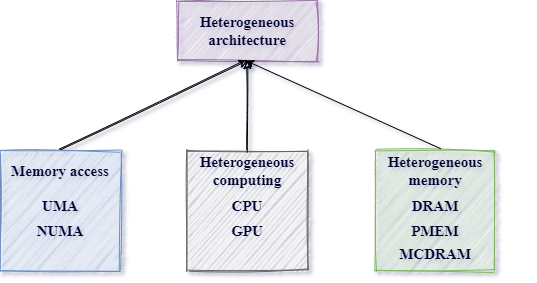
NUMA can be classified as a system with heterogeneous memory access.
However, today’s NUMA Node concept is vaguely comparable to the original one. With the popularization of various types of XPUs (such as CPU, GPU, FPGA, and other accelerators), heterogeneous computing is becoming increasingly relevant. Memory is following suit in this regard and is becoming more and more diverse. The NUMA Node itself, presently, doesn’t have to contain both memory (typically DRAM) and a processing unit (typically a CPU). For example, we can have a memory-only NUMA Node (hot-plugged memory device), which cannot generate memory requests and contains only memory.
Today’s hardware used in platforms is constantly evolving with a broad spectrum of device changes on each level: previously mentioned
processing units, come in the form of, e.g., CPU, GPU, or FPGA. The storage class devices in the form of, e.g., HDD or SSD.
Finally, the memory class devices are provided by physical mediums like DRAM, PMEM, or MCDRAM.
This post focuses on the last aspect of mentioned varieties - on heterogeneous memory.
Memory technology vs memory property
Various physical media offer diverse memory performance characteristics such as latency, bandwidth, or capacity depending on their type and memory bus. However, most applications prefer to leverage memory characteristics rather than specific hardware type to make data placement decisions.
Depending on the currently used memory topology, expected memory behavior could be satisfied by various physical media. This approach allows us to change the point of view from hardware-type-centric into memory-property-centric. With different abstraction types described further in this post, the memkind library will have a hardware-agnostic interfaces.
To overcome memory bounds, we use memory-aware programming, which is an approach already present in OpenMP memory spaces. The following table contains a comparison between hardware, expected memory property associated with it and OpenMP memory spaces:
| Physical medium | Memory property | OpenMP memory spaces |
|---|---|---|
| DRAM | Latency | omp_low_lat_mem_space |
| MCDRAM | Bandwidth | omp_high_bw_mem_space |
| PMem | Capacity | omp_large_cap_mem_space |
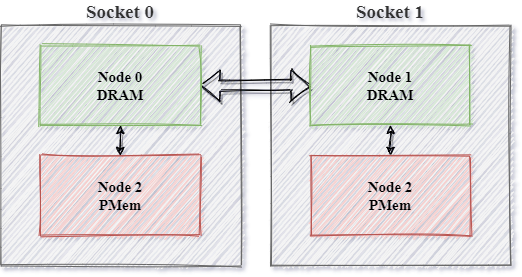
And presented the same view in different form:
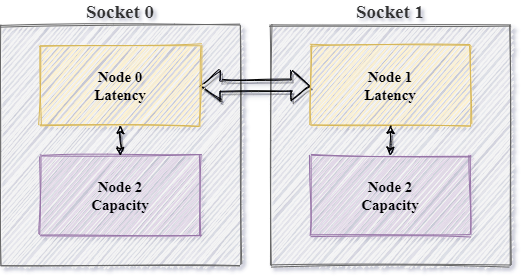
To follow the approach presented in Figure 4, we extend memkind library with additional semantics.
Prerequisites
ACPI-6.2 extends the ACPI standard with Heterogeneous Memory Attribute Table (HMAT). HMAT provides a way for the firmware to propagate memory characteristics to the Operating System - more specifically, it describes bandwidth and latency from the initiator of memory requests (a processor or an accelerator) to any memory target.
HMAT support is required both in hardware and the OS*:
$ make nconfig
Power management and ACPI options --->
[*] ACPI (Advanced Configuration and Power Interface) Support ---> -_- NUMA support
[_] ACPI Heterogeneous Memory Attribute Table Support
*Option CONFIG_ACPI_HMAT is available since Linux Kernel version 5.5
To utilize information provided by the OS, memkind uses hwloc library. It is additional mandatory dependency if you want to use new features offered by memkind.
Memory kind summary
With memkind 1.11.0 release comes support for previously mentioned memory property semantics using the following APIs:
| New API | Associated Memory property |
|---|---|
| MEMKIND_HIGHEST_CAPACITY | Capacity |
| MEMKIND_HIGHEST_CAPACITY_PREFERRED | Capacity |
| MEMKIND_HIGHEST_CAPACITY_LOCAL | Capacity |
| MEMKIND_HIGHEST_CAPACITY_LOCAL_PREFERRED | Capacity |
| MEMKIND_LOWEST_LATENCY_LOCAL | Latency |
| MEMKIND_LOWEST_LATENCY_LOCAL_PREFERRED | Latency |
| MEMKIND_HIGHEST_BANDWIDTH_LOCAL | Bandwidth |
| MEMKIND_HIGHEST_BANDWIDTH_LOCAL_PREFERRED | Bandwidth |
The new semantics choose the best specific memory property presented on different NUMA nodes available on the platform.
What’s new
Locality
So far in memkind library, the existing memory kinds determine the locality as the nearest NUMA based on the shortest NUMA distance metrics. In this strategy, we miss information about Socket and NUMA Node relation. In the case of non-symmetrical memory topology, where, for example, PMEM is placed only on one socket, and we would like to avoid remote memory access - we can use one of the memory kinds from the new API to allocate from memory in local NUMA domain.
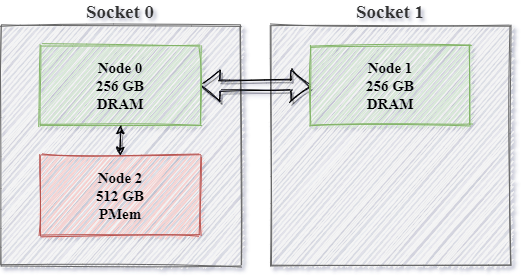
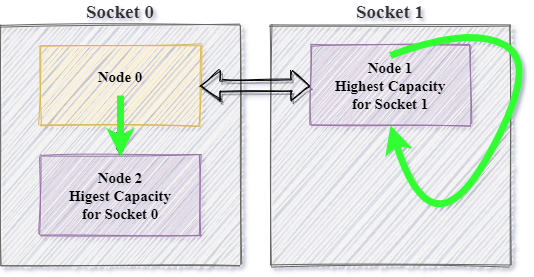
Using MEMKIND_HIGHEST_CAPACITY_LOCAL memkind will allocate to highest capacity Node inside a socket:
New API
Memory property like bandwidth and latency depends on the specific initiator of the memory request. This results in multidimensional analysis based on the different NUMA Node relationships and performance characteristics. Based on this fact, with the new API, memkind addresses different scenarios of potential usage in more complicated memory topologies.
High Bandwidth
To help using legacy API, for MEMKIND_HBW* kinds, we introduced MEMKIND_HBW_THRESHOLD environment variable.
Platforms may have multiple different types of memory, and each offering various bandwidth characteristics to the
initiator of the memory request.
Any NUMA Node with read bandwidth memory property (reported by node’s performance characteristics) above the specific threshold
is considered as high bandwidth. Memkind identify these NUMA Node(s) as a High Bandwidth Memory NUMA Node(s).
MEMKIND_HBW_THRESHOLD provides a mechanism to define the specific value of this threshold.
What’s Coming Next
The idea of NUMA nodes has evolved, and it’s much different now compared to the past version. It no longer focuses on local and remote access. The modern approach is based on a concept with the initiator of a memory request and target of a memory request. Both initiator and target are characterized by different performance properties. CPU is no longer the only entity which can make a memory access. And the same follows for memory – if something performed a memory access, it doesn’t have to come from DRAM.
We believe that more complex memory architectures will become increasingly popular in the future.
With this perspective, a one-dimensional approach based on NUMA distance metrics needs to be revised. At the time of writing this article, Hardware/Firmware architects already defined solutions with HMAT, which means that HMAT-aware platforms are expected to appear in the future. The support for them is available in the Linux Kernel 5.5.
On the application layer, libmemkind tries to meet these challenges with new features presented in this post.