Apache Kudu Persistent Memory Enabled Block Cache
Using NVM Libraries To Add Persistent Memory Support to Apache Kudu Block Cache
An early project done with the NVM libraries was adding persistent memory support, both volatile and persistent mode, into the Apache Kudu storage engine block cache. This project required modification of existing code.
Apache Kudu: https://github.com/apache/kudu
My repository with the modified code: https://github.com/sarahjelinek/kudu, branch: sarah_kudu_pmem
The volatile mode support for persistent memory has been fully integrated into the Kudu source base. The persistent mode support is not integrated but is ready, has been reviewed and is waiting for official integration.
My repository, noted above, has the source for both modes integrated into the kudu project.
High Level Goals
The high level goals of this project were:
- Reduce DRAM footprint required for the Kudu storage engine
- Provide warm cache when data is persistent and tablet server is restarted.
- Keep performance as close to DRAM speed as possible.
Integration Challenges
There were several things considered when designing the integration of PMDK into Kudu:
- Where to integrate SW entry points to access enable persistent memory.
- What data/metadata to store on persistent memory.
- How do you design seamless integration of SW entry points for persistent memory access in an existing application?
- What happens if a failure occurs?
Volatile vs. Persistent Mode Design Differences
- In Volatile mode the LRUHandle entry is stored on the persistent media. Otherwise it’s stored in DRAM.
- In Persistent Mode the addition of a new structure KeyValue was added to store the data persistently and guarantee consistency across failures.
- In all cases the HashTable is stored in DRAM.
Why these design differences?
- The LRUHandle is common for all three modes of the Kudu block cache (DRAM, persistent memory volatile mode and persistent memory persistent mode). The LRUHandle was initially designed for the DRAM block cache and I just carried that design forward. This handle is used by other components of Kudu and changing the structure of it would have required more changes in other parts of Kudu.
- It was a straightforward process to simply store the LRUHandle in persistent memory when running in volatile mode since I did not have to worry about consistency in the event of a failure. At the start of this project the only NVM library support that was available was libvmem and I made my initial design decisions based on that.
- Once I started adding the persistent mode support I realized that changes would have to be made to the LRUHandle structure to manage consistency and to separate out the methods that are part of the C++ struct. For storing key/value data this was unnecessary.
In hindsight I would go back and use the KeyValue structure for both volatile and persistent mode support and keep the LRUHandle in DRAM in all cases.
I never considered putting the hash table on persistent memory. I didn’t feel there was a need to do this to reach the goals of the project.
Kudu Architectural Overview
Kudu is an open source storage engine for structured data which supports low-latency random access together with efficient analytical access patterns.
High Level Concepts and Terms
Columnar Data Store Kudu is a columnar data store. A columnar data store stores data in strongly-typed columns.
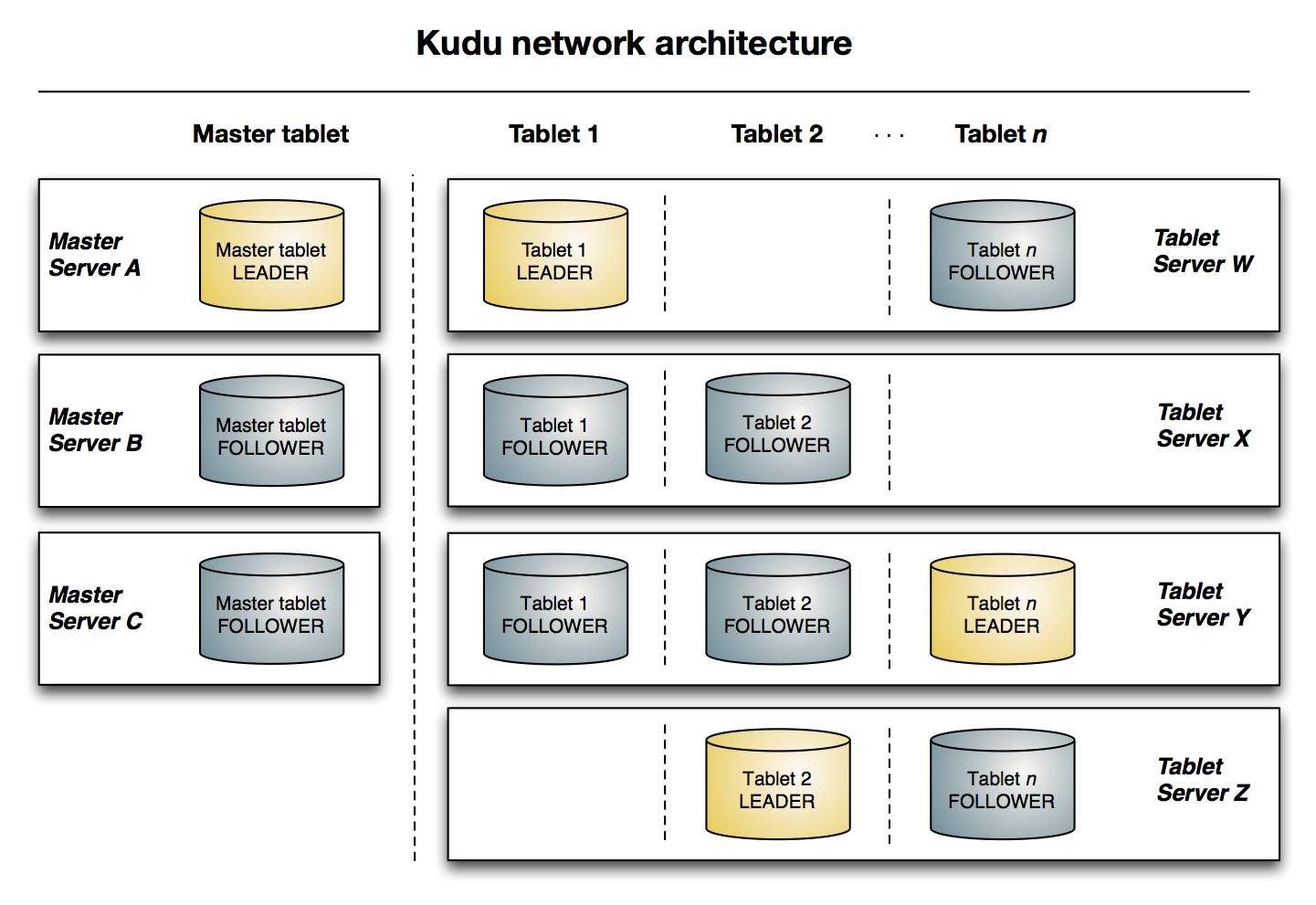
Tablet A tablet is a contiguous segment of a table, similar to a partition in other data storage engines or relational databases. A given tablet is replicated on multiple tablet servers, and at any given point in time, one of these replicas is considered the leader tablet. Any replica can service reads, and writes require consensus among the set of tablet servers serving the tablet.
Tablet Server A tablet server stores and serves tablets to clients. For a given tablet, one tablet server acts as a leader, and the others act as follower replicas of that tablet. Only leaders service write requests, while leaders or followers each service read requests. Leaders are elected using Raft Consensus Algorithm. One tablet server can serve multiple tablets, and one tablet can be served by multiple tablet servers.
Master The master keeps track of all the tablets, tablet servers, the Catalog Table, and other metadata related to the cluster. At a given point in time, there can only be one acting master (the leader). If the current leader disappears, a new master is elected using Raft Consensus Algorithm.
Kudu Block Cache
As part of every tablet server Kudu provides a LRU block cache. Conceptually the design looks as follows(with the inclusion of persistent memory support):
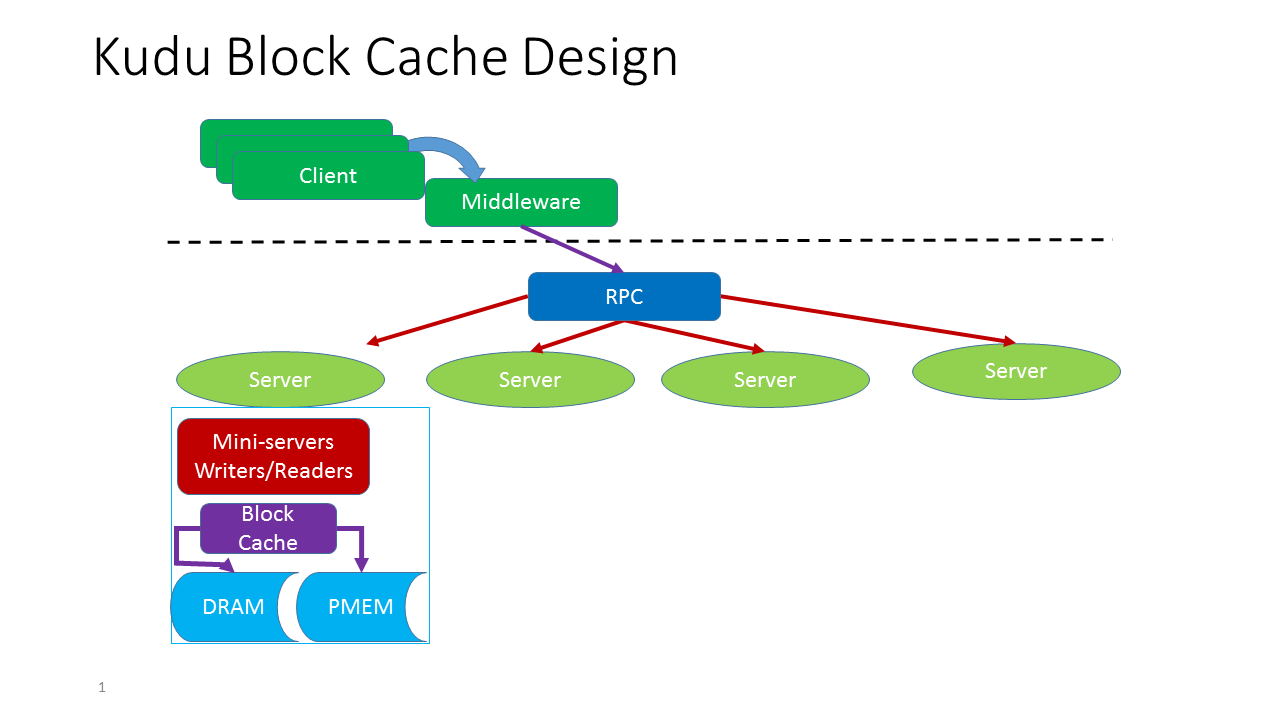
Each tablet server has one block cache. The Kudu Block Cache is an interface that maps keys to values. It has internal synchronization and may be safely accessed concurrently from multiple threads. It may automatically evict entries to make room for new entries. Values have a specified charge against the cache capacity.
Persistent Mode Support
The rest of this blog post addresses the details of the Persistent Mode support.
To Transact or not to Transact
The NVM libpmemobj library provides the interfaces to allocate and manage the persistent memory object store. This library provides both atomic allocation functions and transactional object manipulation functions.
In general terms, transaction processing is information processing that is divided into individual, indivisible operations called transactions. Each transaction must succeed or fail as a complete unit; it can never be only partially complete. Using the transactional object interfaces in libpmemobj allows the programmer to worry less about the consistency of the data in the event of a failure. As long as the transactions are coded correctly it is guaranteed that anything inside the TX_BEGIN and TX_END block using libpmemobj are indivisible operations. They either succeed or fail as a whole.
libpmemobj provides atomic memory management interfaces as well. These functions guarantee that within the scope of the function the operation is atomic. For example, calling pmemobj_alloc(…) is guaranteed to allocate the entire object or fail to allocate the entire object but will never leave a partial object in place.
For the Kudu block cache I chose to use the atomic memory allocation rather than transactions. Why? There were a few reasons doing it this way made more sense for this application.
When the block entry is not found in the cache memory is allocated from the cache. The memory allocation can fail with the persistent memory cache. This cache has a hard size limit and a defined number of retries before it gives up on the allocation. If a transaction was opened and held during the time of the retry multiple threads would be blocked on the transaction since memory allocation is an exclusive operation in the block cache. It is locked by a mutex so that others cannot allocate memory out from underneath a competing thread.
Once the memory was allocated, while the initial transaction was open, the data would have to be read from slower media prior to insertion into the cache. The IO could stall and keep the transaction open for an unacceptable period of time.
The overhead of the transactions was not necessary based on the size of and scope of the data structure that is being used to store the key/value data.
This was the least invasive way to add the use of persistent memory into the Kudu block cache.
Technical Details
Key Kudu Block Cache Data Structures
LRUHandle
Each Kudu block cache entry has an associated LRUHandle instance. The LRUHandle is the object that represents the block cache entry to other Kudu components. My design keeps the LRUHandle instances in DRAM when operating in persistent mode. When the Kudu block cache is using persistent media but running in volatile mode the LRUHandle structures are store on the persistent media.
// LRU cache implementation
// An entry is a variable length heap-allocated structure when running in volatile
// mode. When operating in persistent mode the structure is fixed length.
// The entries are kept in a circular doubly linked list ordered by access time.
// For persistent memory there are two use cases for allocation of the LRUHandle.
// 1. When running in volatile mode the LRUHandle as well as the key and
// value data are is allocated from the volatile persistent memory pool.
// It is managed as part of the pool. This is similar behavior to the DRAM cache.
// 2. When running in persistent mode the LRUHandle is allocated from DRAM.
// In either case the LRUHandle is never persisted.
// 3. When running in persistent mode the key and value data are stored in persistent memory.
//
// Entries are kept in a circular doubly linked list ordered by access time.
struct LRUHandle {
Cache::EvictionCallback* eviction_callback;
LRUHandle* next_hash;
LRUHandle* next;
LRUHandle* prev;
size_t charge;
uint32_t key_length;
uint32_t val_length;
Atomic32 refs;
uint32_t hash; // Hash of key(); used for fast sharding and comparisons
uint8_t* kv_data; // Either pointer to pmem or space for volatile pmem.
// This is set when an entry is created from an existing persistent
// cache entry.
bool repopulated;
Slice key() const {
return Slice(kv_data, key_length);
}
Slice value() const {
return Slice(&kv_data[key_length], val_length);
}
uint8_t* val_ptr() {
return &kv_data[key_length];
}
};
HashTable
The Kudu block cache has a hash table of the LRUHandle entries.
// We provide our own simple hash table since it removes a whole bunch
// of porting hacks and is also faster than some of the built-in hash
// table implementations in some of the compiler/runtime combinations
// we have tested. E.g., readrandom speeds up by ~5% over the g++
// 4.4.3's builtin hashtable.
class HandleTable {
public:
HandleTable() : length_(0), elems_(0), list_(NULL) { Resize(); }
~HandleTable() { delete[] list_; }
LRUHandle* Lookup(const Slice& key, uint32_t hash) {
return *FindPointer(key, hash);
}
LRUHandle* Insert(LRUHandle* h) {
LRUHandle** ptr = FindPointer(h->key(), h->hash);
LRUHandle* old = *ptr;
h->next_hash = (old == NULL ? NULL : old->next_hash);
*ptr = h;
if (old == NULL) {
++elems_;
if (elems_ > length_) {
// Since each cache entry is fairly large, we aim for a small
// average linked list length (<= 1).
Resize();
}
}
return old;
}
LRUHandle* Remove(const Slice& key, uint32_t hash) {
LRUHandle** ptr = FindPointer(key, hash);
LRUHandle* result = *ptr;
if (result != NULL) {
*ptr = result->next_hash;
--elems_;
}
return result;
}
private:
// The table consists of an array of buckets where each bucket is
// a linked list of cache entries that hash into the bucket.
uint32_t length_;
uint32_t elems_;
LRUHandle** list_;
// Return a pointer to slot that points to a cache entry that
// matches key/hash. If there is no such cache entry, return a
// pointer to the trailing slot in the corresponding linked list.
LRUHandle** FindPointer(const Slice& key, uint32_t hash) {
LRUHandle** ptr = &list_[hash & (length_ - 1)];
while (*ptr != NULL &&
((*ptr)->hash != hash || key != (*ptr)->key())) {
ptr = &(*ptr)->next_hash;
}
return ptr;
}
void Resize() {
uint32_t new_length = 16;
while (new_length < elems_ * 1.5) {
new_length *= 2;
}
LRUHandle** new_list = new LRUHandle*[new_length];
memset(new_list, 0, sizeof(new_list[0]) * new_length);
uint32_t count = 0;
for (uint32_t i = 0; i < length_; i++) {
LRUHandle* h = list_[i];
while (h != NULL) {
LRUHandle* next = h->next_hash;
uint32_t hash = h->hash;
LRUHandle** ptr = &new_list[hash & (new_length - 1)];
h->next_hash = *ptr;
*ptr = h;
h = next;
count++;
}
}
DCHECK_EQ(elems_, count);
delete[] list_;
list_ = new_list;
length_ = new_length;
}
};
KeyValue
// This is a variable length structure. The length of the structure is
// determined by the key and value sizes. This structure is the physical entry
// that is persisted as the pmemobj object.
struct KeyVal {
uint32_t key_len;
uint32_t value_len;
uint8_t pad[3];
// Size of the valid member is set so that the alignment will be always
// 24 bytes up to the flexible array. This is required for the persistent memory
// allocator to do the right thing in terms of alignment.
// This member is set at the very end prior to persisting the KeyVal
// object. This means that in the case of an interruption in service
// the pmemobj object is not considered complete.
// If 'valid' is not set then upon restart this entry is discarded.
uint8_t valid;
uint8_t kv_data[]; // holds key and value data
};
Kudu Cache Lookup and Insert
The Kudu block cache is updated on lookup. If the data is not found in the tablet server block cache it is read from the media and added to the block cache as a result. For the persistent memory implementation this means that we must allocate the buffer for the key/value data from the persistent memory media. We do this rather than allocating DRAM and then copying the information from DRAM to the persistent memory media.
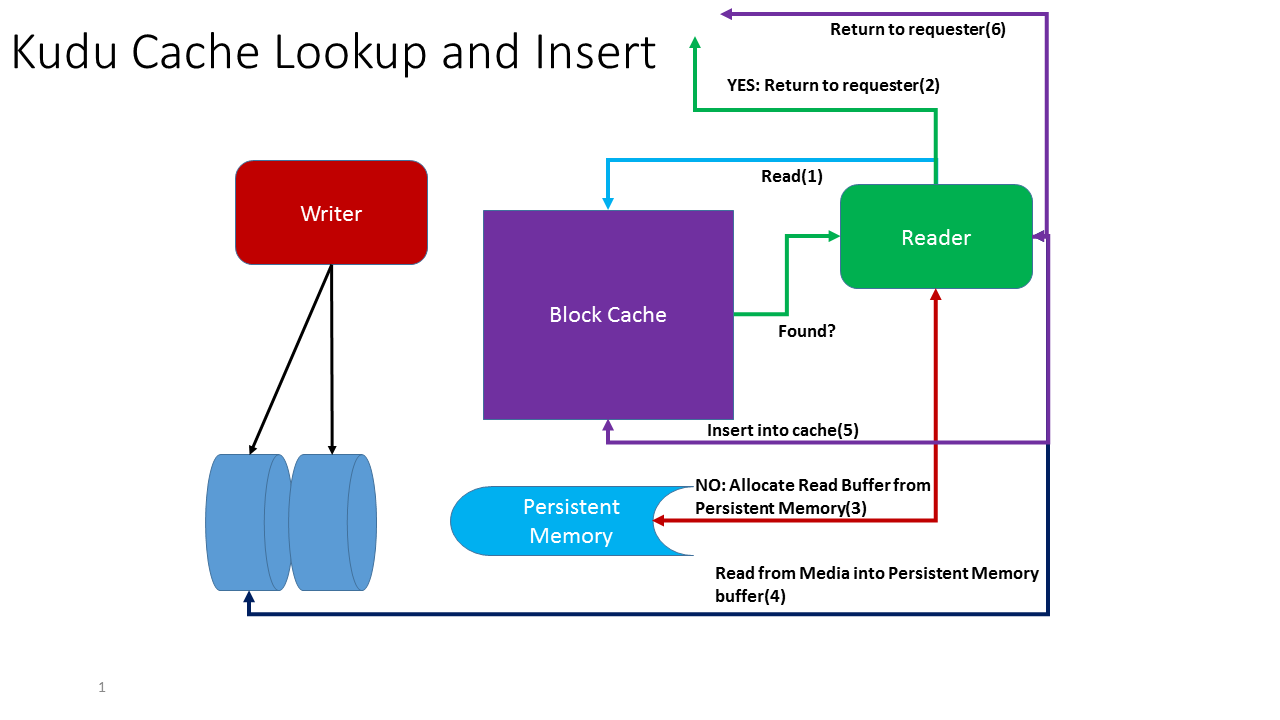
Persistent Memory Constructor
With atomic memory allocation a constructor is required to ensure that the initial memory allocation is done atomically as defined by the user. I have defined atomic in this case to be: a) creation of the KeyVal structure, setting kv->valid = 0 and then persisting the value of kv->valid to ensure that until this bit it set to 1 this KeyVal instance is not considered valid.
The kv_data[] member holds both the key and value data, and are simply found by knowing the length of the key and value members. At the time of allocation the key value is known, the size of the data is known but the data has not been read from the media. The kv_data[] data value is filled in by reading the data from the disk during the read operation.
int KvConstructor(PMEMobjpool* pop, void* ptr, void* arg) {
struct KeyVal* kv = static_cast<struct KeyVal*>(ptr);
kv->valid = 0;
pmemobj_persist(pop, &kv->valid, sizeof(kv->valid));
return 0;
}
Cache Insertion
At this point the memory has been allocated, the key and value data have been written, not persistently however, prior to insertion. Persisting the structure and its data is delayed until this point because until the entry is inserted into the cache it is not valid. The largest size to persist is the data itself so persisting the whole structure at one time as opposed to smaller parts does not result in performance degradation.
Cache::Handle* NvmLRUCache::Insert(LRUHandle* e, Cache::EvictionCallback* eviction_callback) {
if (IsPersistentMode() && !e->repopulated) {
// At the time of insertion we know we have succeeded in allocating
// the pmem space we need. So, there will be an persistent object
// created for this memory address.
struct KeyVal* kv =
reinterpret_cast<struct KeyVal*>(e->kv_data - offsetof(KeyVal, kv_data));
if (!kv->valid) {
kv->key_len = e->key_length;
kv->value_len = e->val_length;
kv->valid = 1;
// At this point we have a fully populated struct KeyVal but none of it has been
// persisted, except the initial kv->valid bit set to 0 in the constructor.
// We persist the structure + key and value data here once prior to setting
// the valid bit. At any point in time prior to this we can fail and the
// valid bit will be set to 0 indicating that the structure is not usable.
pmemobj_persist(pop_, kv, sizeof(struct KeyVal) + e->key_length + e->val_length);
}
}
// Populate the cache handle.
PopulateCacheHandle(e, eviction_callback);
return reinterpret_cast<Cache::Handle*>(e);
}
Failures can occur at any point in time during the operation of the application. At all time prior to setting kv->valid = 1 and calling pmemobj_persist() the entry is not considered valid and upon restart will be discarded.
Restart of Tablet Server and Repopulating the Cache
Lastly I want to discuss how the cache is repopulated in the event of a shutdown and restart of the tablet server. At cache startup the cache creation code looks for any existing entries and iterates over them to repopulate the volatile data structures associated with the valid persistent cache entry.
if (IsPersistentMode()) {
TOID(struct KeyVal) kv;
// Populate a shard with existing entries(if any). A nullptr value breaks
// us out of the loop, and means that there are no entries.
// Since there are multiple object types in the pool we use the FOREACH_TYPE
// and filter only on the TOID(struct KeyVal).
POBJ_FOREACH_TYPE(pop_, kv) {
if (D_RO(kv) == nullptr) {
// This will only happen if there are no entries in the pool.
break;
}
if (D_RO(kv)->valid == 1) {
LRUHandle* e = new LRUHandle;
e->kv_data = const_cast<uint8_t*>(D_RO(kv)->kv_data);
e->key_length = D_RO(kv)->key_len;
e->val_length = D_RO(kv)->value_len;
e->hash = HashSlice(e->key());
e->charge = sizeof(struct KeyVal) + D_RO(kv)->key_len + D_RO(kv)->value_len;
e->repopulated = 1;
Insert(reinterpret_cast<PendingHandle*>(e), nullptr);
} else {
POBJ_FREE(&kv);
}
}
}
}
This code is fairly straightforward to read. I simply iterate over the object type I am interested in, which is a ‘struct KeyVal’, and look for entries that are marked valid. Any entry found that is not marked valid is discarded.
There were three high level goals stated at the beginning of this blog post, High Level Goals. The next post will provide details on the performance and DRAM reduction using the PMDK libraries to enable persistent memory support in the Kudu block cache.