Zero-copy leaf splits in pmemkv
In a B+ tree, splitting a full leaf into two leaves is one of its slowest operations, but pmemkv optimizes this using a zero-copy strategy. Rather then copying any key/value data between full and new leaf, pmemkv splits leaves by swapping persistent structures in place. This minimizes write amplification and increases performance compared to copying, especially for larger key/value sizes.
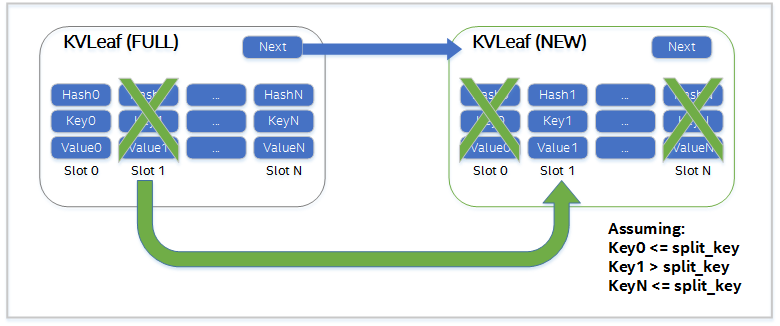
The diagram below illustrates a persistent leaf being split. A ‘slot’ is the term used in pmemkv for the grouping of a key, the Pearson hash for the key, and the value for the key. During the split, slots having keys that sort below or equal to the split key are untouched, but those slots in the new leaf are marked unused. Slots where keys sort above the split key have to be relocated to the new leaf, and those original slots in the full leaf are marked unused.
The main loop of the leaf split method, if reduced down to the relevant details, looks like the code below.
for (int slot = LEAF_KEYS; slot--;) {
if (strcmp(leaf->keys[slot].c_str(), split_key.data()) > 0) {
// relocate slot data to new_leaf
}
// else do nothing, slot in new_leaf is already marked unused
}
Note that memory allocated by libpmemobj is always zero-filled, and a zero-filled slot is considered unused by convention. So there is no need to explicitly clear slots on a new leaf during a split. This explains why the loop above skips any slot where the key sorts below or equal to the split key.
Now that we’ve framed the problem of splitting persistent leaves, the rest of this post will cover three solution strategies: naive copy, copy-or-swap, and zero-copy. (hint: the last one is best!)
Leaf splits using naive copy
Our optimization story begins with
pmemkv
using persistent leaves (KVLeaf) composed of separate arrays for
hashes, keys, and values. Keys and values are modeled using a basic
persistent string class
(KVString) that allows getting/setting the contents as a
C-style string.
class KVString {
public:
char* data() const;
void reset();
void set(const char* value);
};
struct KVLeaf {
p<uint8_t> hashes[LEAF_KEYS];
p<KVString> keys[LEAF_KEYS];
p<KVString> values[LEAF_KEYS];
persistent_ptr<KVLeaf> next;
};
The main loop of the leaf split method uses KVString::set
to copy data between leaves, and then KVString::reset to mark
a slot string as unused.
for (int slot = LEAF_KEYS; slot--;) {
if (strcmp(leaf->keys[slot].c_str(), split_key.data()) > 0) {
// copy key to new leaf
KVString slot_key = leaf->keys[slot].get_rw();
new_leaf->keys[slot].get_rw().set(slot_key.data());
// copy value to new leaf
KVString slot_value = leaf->values[slot].get_rw();
new_leaf->values[slot].get_rw().set(slot_value.data());
// reset original leaf slot
slot_key.reset();
slot_value.reset();
leaf->hashes[slot] = 0;
}
}
For small keys and values (that fit within the KVString SSO buffer),
this approach works nicely.
Leaf splits using copy-or-swap
As keys and values increase in size (to hundreds or thousands of bytes), copying strings during a leaf split gets increasingly expensive. The overhead comes not just from copying, but because all these copies and resets are also journaled in case the persistent transaction gets rolled back.
Luckily the p<> wrapper (in this case p<KVString>) offers a swap
method that switches two persistent structures in place without
copying all the data held by the structures. Exactly what we need!
We can now implement a copy-or-swap scheme by first adding KVString
methods to read if the string is short or long, and to provide a special
setter method for when the string is known to be short.
class KVString {
public:
char* data() const;
bool is_short() const; // added
void reset();
void set(const char* value);
void set_short(const char* value); // added
};
struct KVLeaf { // not changed from prior version
p<uint8_t> hashes[LEAF_KEYS];
p<KVString> keys[LEAF_KEYS];
p<KVString> values[LEAF_KEYS];
persistent_ptr<KVLeaf> next;
};
The main loop of the leaf split method is changed to either copy a string
(if the string is sufficiently short) or simply swap KVString instances
(when the string is long).
for (int slot = LEAF_KEYS; slot--;) {
if (strcmp(leaf->keys[slot].c_str(), split_key.data()) > 0) {
// copy or swap key
const KVString slot_key = leaf->keys[slot].get_ro();
if (slot_key.is_short()) {
new_leaf->keys[slot].get_rw().set_short(slot_key.data());
} else new_leaf->keys[slot].swap(leaf->keys[slot]);
// copy or swap value
const KVString slot_value = leaf->values[slot].get_ro();
if (slot_value.is_short()) {
new_leaf->values[slot].get_rw().set_short(slot_value.data());
} else new_leaf->values[slot].swap(leaf->values[slot]);
// reset original leaf slot
leaf->hashes[slot] = 0;
}
}
Using a copy-or-swap strategy is significantly faster than doing naive copies, but we can still improve performance and reduce write amplification even more.
Leaf splits using swap
A zero-copy strategy that relies purely on p.swap() is generally the
fastest and most efficient, but this requires some refactoring of our
persistent structures to accomplish.
Rather than treating a ‘slot’ as just a logical grouping, we introduce
a KVSlot type to replace KVString. KVSlot maintains
hash, key, and value in a single data structure that also includes
key and value length. Where KVLeaf before had separate arrays for
hashes, keys and values, now KVLeaf has a single KVSlot array,
and each KVSlot has a single persistent buffer to store both key
and value data.
class KVSlot {
public:
void clear();
uint8_t hash() const;
const char* key() const;
const char* val() const;
void set(const uint8_t hash, const string& key, const string& value);
private:
uint8_t ph; // Pearson hash for key
uint32_t ks; // key size
uint32_t vs; // value size
persistent_ptr<char[]> kv; // buffer for key & value
};
struct KVLeaf {
p<KVSlot> slots[LEAF_KEYS];
persistent_ptr<KVLeaf> next;
};
The main loop of the leaf split method is now trivial!
for (int slot = LEAF_KEYS; slot--;) {
if (strcmp(leaf->slots[slot].key(), split_key.data()) > 0) {
new_leaf->slots[slot].swap(leaf->slots[slot]);
}
}
Impacts on Performance and Storage Efficiency
Let’s close with some rough numbers to better compare the copy-or-swap
strategy with KVString against the zero-copy strategy with KVSlot.
(The naive copy strategy is too slow to consider)
For sequential insertion of 20-byte keys with 800-byte values, using
emulated persistent memory,
total workload time improved by 37% when switching from
KVString to KVSlot in my testing.
Storage efficiency for 20-byte keys with 800-byte values
improved by 20% switching from KVString to KVSlot. This is because
KVSlot always requires one persistent buffer, where KVString would
have required two persistent buffers per slot for this workload.
KVSlot also has no SSO buffers that go to waste for large values,
which is true of KVString.
However, storage efficiency when testing 20-byte keys with 15-byte values
decreased by 35% when switching from KVString to KVSlot. This is because
KVString has an internal SSO buffer that requires no additional
allocations in the case of short strings. KVString also saves space
by not storing string length as a persistent field but assuming use
of strlen instead.
Conclusions
The zero-copy strategy using KVSlot is the obvious path for
pmemkv
moving forward, and by the time you read this, all these changes
will be available on our
GitHub repo.
Gains in both Put operation performance (our slowest operation)
and storage efficiency for larger strings easily outweigh losses in
storage efficiency for the specific case of very small strings. This
seems like the right tradeoffs for the large and semi-structured
datasets that we’d like to enable with pmemkv.