Performance improvements
I would like to inform you about the performance improvements that have been going on in PMDK and libpmemobj in particular. We have not been standing still and we are trying out a couple of ideas on how to make our libraries even faster. Some of the improvements are smaller, some are larger. Some of them have already made it to the master branch and some are just ideas on how to rework the internals of libpmemobj to make it even faster. All measurements were made on a two socket, sixteen core machine.
Pmemobj allocations’ thread scaling
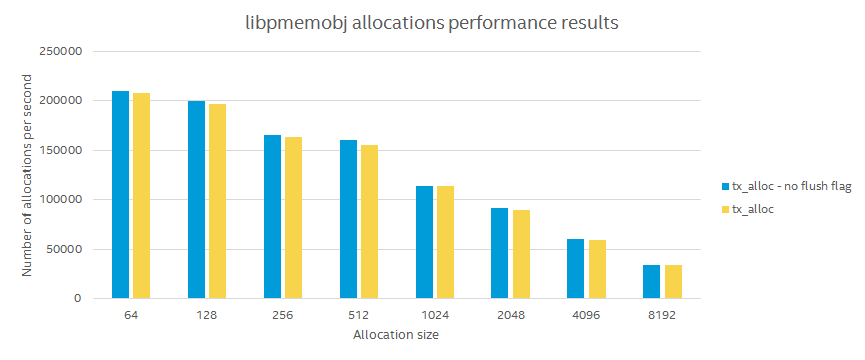
The first thing we noticed, is that allocations aren’t scaling properly to the expected twice the number of logical CPUs.
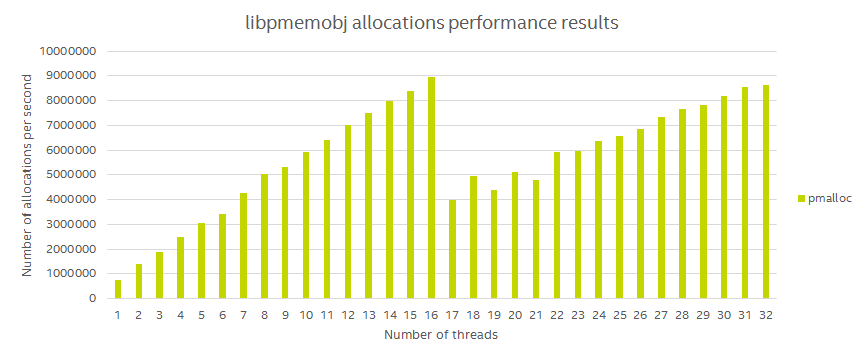
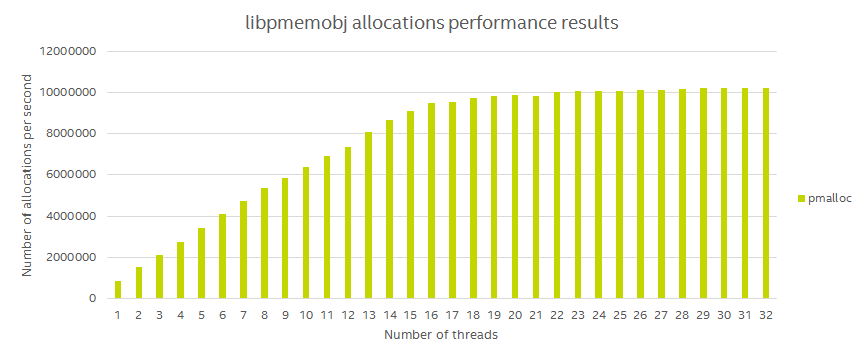
After a very simple fix, the thread scaling is magically fixed.
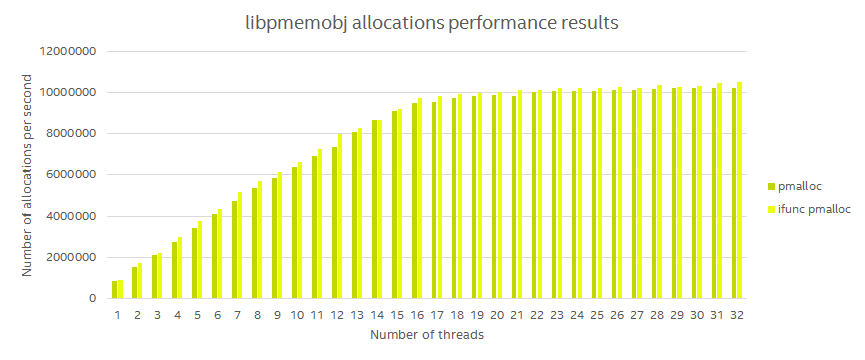
Function pointers
During the performance analysis we made recently, we noticed that calling functions through pointers adds a considerable overhead, especially for fast and frequently called functions. We decided to reduce the number of function pointer calls and additionally use the GCC ifunc attribute where appropriate. This yields, on average, a 2% performance gain in our synthetic benchmarks.
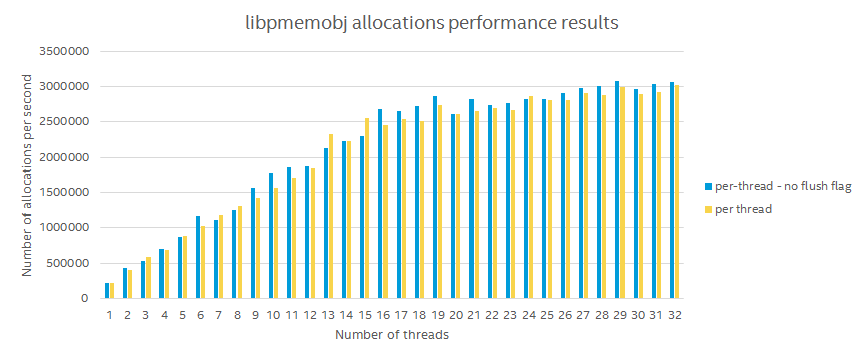
Redo log optimizations
We also noticed, that we could slightly improve the redo log flushing mechanism in certain scenarios. When you change sections of persistent memory which is on the same cache line, you don’t need to flush them multiple times. This can be used, for example, when updating the OOB header. This yields an additional 2% performance gain.
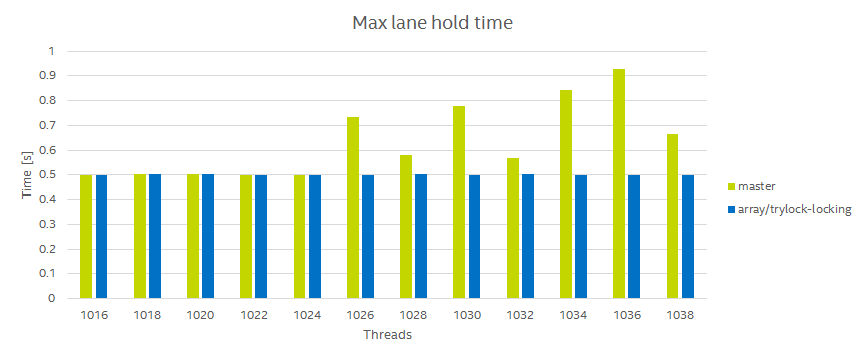
The thread starvation problem
One other issue spotted during the performance analysis, is the possibility of starving one of the threads, should a lane not be released. This can happen when a thread takes a lane indefinitely, then at some point, a different thread will be locked waiting on the lane mutex. The chart below represents a test where all threads are performing some action (sleeping to be exact) for an average duration of 0.5 seconds. As we go over the number of available lanes (1024), we see that the max execution time goes well over half a second.
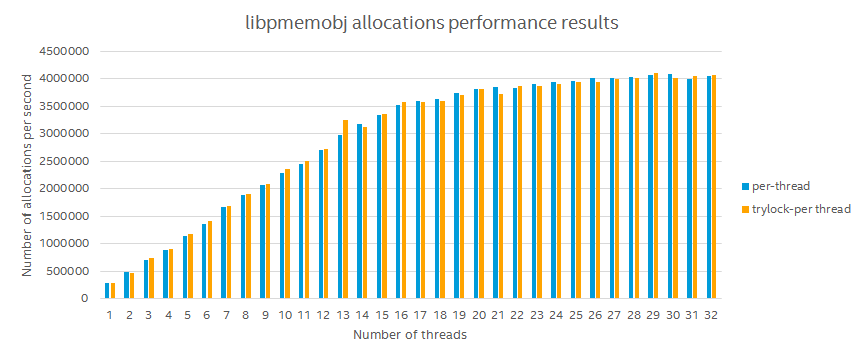
The simplest solution to this, is to use pthread_mutex_trylock and that is in fact the first approach we took. The performance did not suffer any penalty.
We are however not content with the speed of this mechanism, therefore we started to come up with a “simpler” solution based on the compare and swap operation. The initial implementation yields a significant performance improvement, however it is not safe for applications which operate on two or more pools in the same thread.
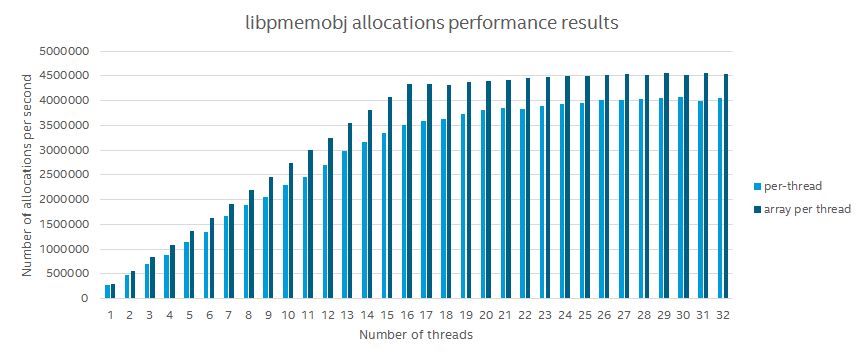
We are still working on this, because it could greatly improve performance, especially for highly multi-threaded applications.
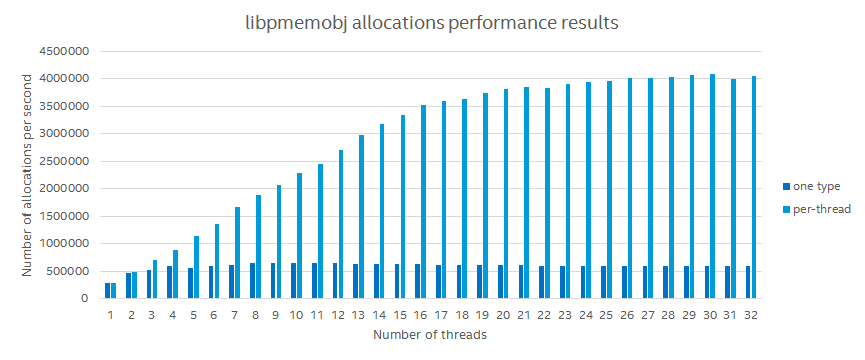
Allocations and type numbers
In libpmemobj we have this notion of type numbers. This is among other things used to internally locate objects of a given type. Users of libpmemobj should however be wary of a possible huge performance drop, should the typenum be neglected and all objects used the same type. On the chart below one data series uses one type number for all threads and the other one allocates on a type-per-thread basis. Don’t fret though, we think we have a solution for this.
Summary
We are constantly looking for places where we could improve the performance of PMDK and libpmemobj in particular. For example, we are thinking of redoing the whole internal object storage module and we hope to gain some additional percents there. If you have any other idea, let us know in pmem/issues, or better yet, do a pull request!