An introduction to replication
Replication is a means for raising the reliability of your pmemobj based applications. You can basically think of it as RAID 1 within PMDK. What happens is, when you write to your pool using the pmemobj_* (memcpy, persist, and so on) primitives, it gets copied to your replicas. Yes, you can have more than one replica. In fact you can have as many as you want, but you have to keep in mind the performance penalty.
Replication, although not directly, is related to pool sets. This is a simple concept which I will try to briefly explain.
Replication and pool sets
Imagine you want to create a really big pmemobj pool, so big that it exceeds the capacity of a single non-volatile memory device. However, you have more than one of those and would like to leverage that fact. Well, now you can. Taken from the libpmemobj manual: “The libpmemobj allows building transactional object stores spanning multiple memory devices by creation of persistent memory pools consisting of multiple files, where each part of such a pool set may be stored on different pmem-aware filesystem”. That just about sums it up.
As you might have noticed, I specifically mention pmemobj pools. That is because we only support this feature for libpmemobj. There is in fact no technical obstacle keeping us from supporting this feature for the other libraries in PMDK, but we decided to do it one step at a time. One other constraint is that for now we only envision local replication. What I mean is not that you cannot do remote replication, just that we don’t have any native support in the library itself. If you have a remote filesystem that supports the mmap() syscall, it should be OK to put replicas there. If you have a setup like that and experience issues using replication, let us know in our issues section.
Replicas can also be made of multiple files, just like your primary pool. These two features in combination give you a lot of leeway in the way you compose and backup your pmemobj pools. These are two powerful concepts.
How to set-up replication
There are two ways of setting up your replica/pool set. As you might expect, one is the easy and preferred way and one is the opposite. You can do it using the pmemobj_create() function. You have to keep in mind that it has to point to a well formed set file (more on that later) and that the poolsize argument must be equal to 0. Other than that it is a standard pmemobj_create() call. The mode parameter applies to all the files created from the set file (both the primary set and the replicas). This a perfectly valid approach, but we prefer doing this using the pmempool tool. In fact this is the preferred way of doing administrative tasks on any type of pool. It’s less error prone and less of a hassle to create/manage/debug your pools. I suggest you get acquainted with it. Also, expect a blog entry on it, once the features it supports and the tool itself stabilize.
As I mentioned before, to create a set/replica you need a .set file. The way this file is composed is subject to change (especially if we implement support for some kind of remote replication) so I urge you to look at our manpages. Let’s take a look at an example.
PMEMPOOLSET
# first set/replica foo
100G /mountpoint0/foo.part0
200G /mountpoint1/foo.part1
400G /mountpoint2/foo.part2
REPLICA
# second set/replica bar
500G /mountpoint3/bar.part0
200G /mountpoint4/bar.part1
REPLICA
# third set/replica baz
800G /mountpoint5/baz.part0
This represents a 700GB pool set and two replicas. As you probably noticed, the number of files in the replicas, as well as the cumulative size of each part do not have to match. The library will chose the size of the smallest set as the actual pool size. All of the replicas are binary copies and are interchangeable. This is however not hassle-free and should be done by an external tool - pmempool (it does not have support for this yet, but we plan to implement it). The first line of the set file has to be PMEMPOOLSET - don’t try to put a comment there.
Once you have the set file ready and have appropriate permissions to all the mountpoints, run the pmempool tool to create all the necessary files.
pmempool create --layout="mylayout" obj myobjpool.set
If pmempool does not report an error, you’re good to go, to do a pmemobj_open on the set file and use your pool.
How does it perform?
Pool replication is a very neat feature, but it shouldn’t be abused. Adding replicas has a quite substantial, unavoidable performance penalty. Let me show you exactly what I mean. I ran the pmembench_map, pmemobx_tx and pmalloc benchmarks from the PMDK tree to see what replication does to performance. These are pretty much the standard benchmarks made to work with my custom set with replication. Do not look at the absolute values, but the difference between the number of operations per second as a function of replicas. Depending on the algorithm used, the overhead is different and not always a show-stopper. Our current implementation of replication basically does a binary copy of the original pool, hence the possible differences.
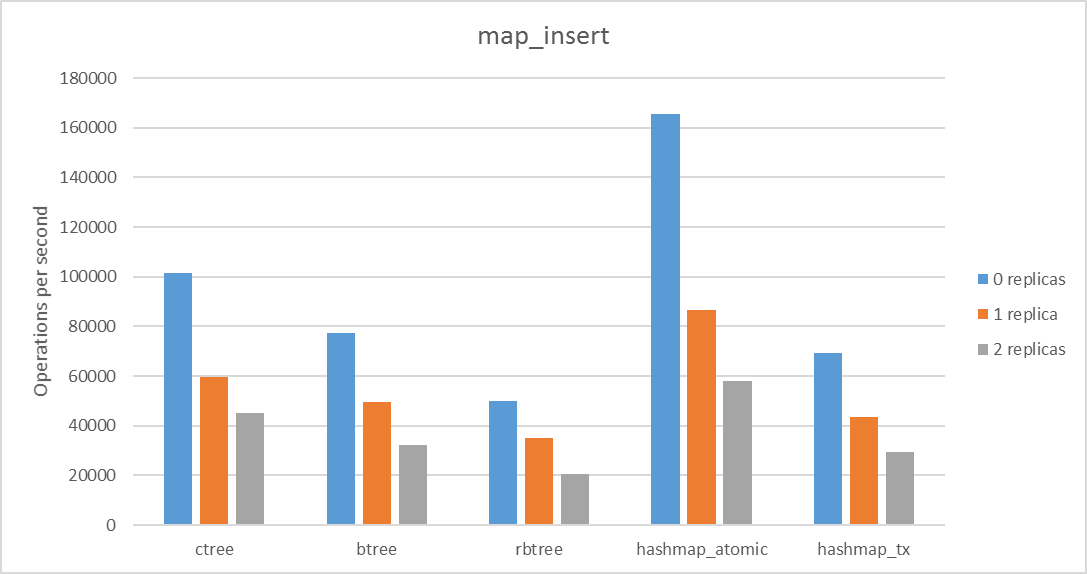
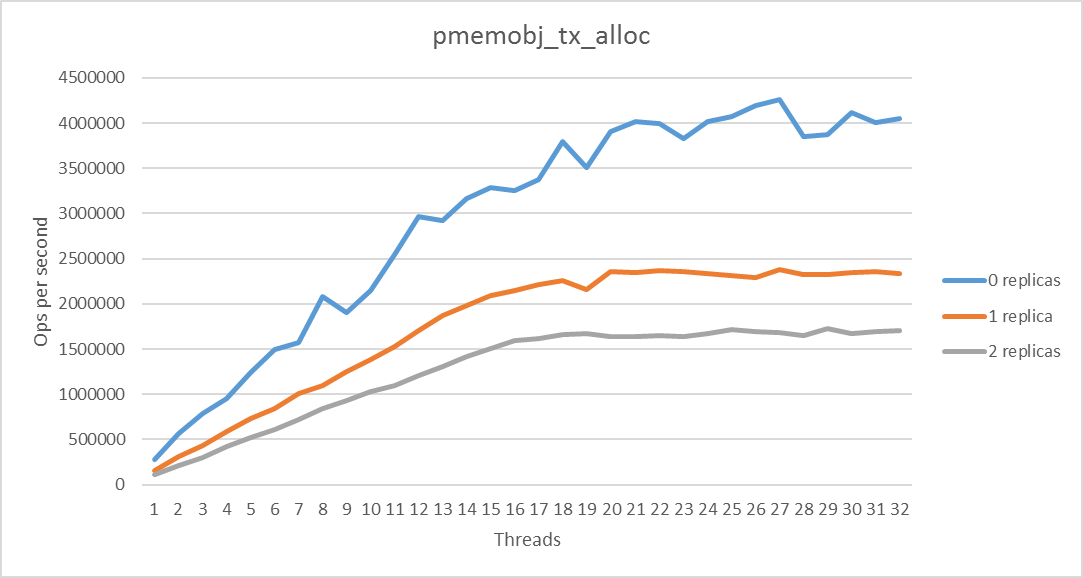
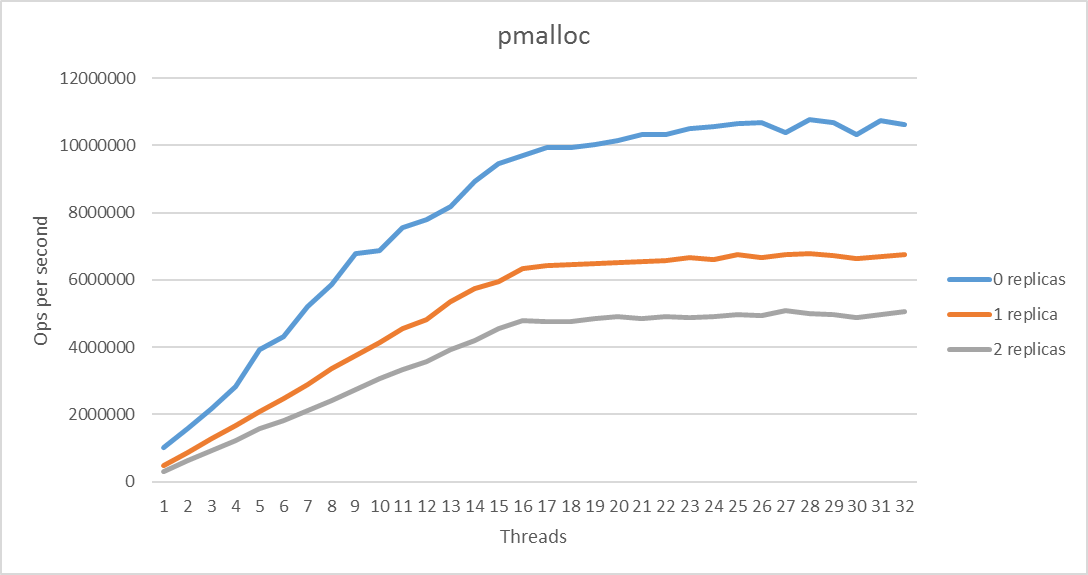
Further plans
For now, we envision adding more administrative functions to the pmempool tool. We would like to enable adding/removing replicas to an active set, changing the partitioning between files. For now, this is not supported and you have to start the new set from scratch each time you decide to make a change. Another thing worth considering is an interactive .set file creator.
We plan on supporting basic 1:1 remote replication using standard network transports. The design of the remote replication will be such that existing PMDK based applications that utilize 1:1 local replication can also utilize 1:1 remote replication without changes to the application.