Challenges of multi-threaded transactions
Our library currently does not support threads cooperating (writing) within a single transaction. It does shift a lot of work from the library onto the user who now has to think about different parallelization solutions.
This was a conscious decision with iterative approach to creating the library in mind. It was far easier to implement the current transaction support strategy and say that it works with relatively good performance than it would be to implement multi-threaded transactions straight up and say that they work and scale linearly with CPUs thrown at them (yea right). The required validation effort alone would be tremendous.
Good news is that our code-base is ready for fully scalable transactions implementation and we didn’t abandon the idea. In fact, my personal interest on the topic was recently renewed by the paper recently published by HP Labs. It’s a good read, I genuinely recommend it.
The problem
Our undo log is a list of data structures that contain the three things:
offset of the memory range, its size and the data itself. This list is
persistent. Meaning that every insert/remove operation is failsafe atomic.
And since we don’t have “compare, swap and persist” operation it’s really
not possible to make the list persistent and lock-free. Hence there’s a list
mutex that has to be acquired for every operation. This means that sharing this
list with multiple threads trying to write to it would basically kill any scaling
by serializing on that mutex.
Solution to that is easy, just give every thread its own list. But now there’s
an issue of what happens on recovery. Which list do we recover first? We need to
recover the state of the memory pool to be exactly like before the transaction
has started, for a single list that is relatively easy because we can just traverse
the list in reverse. For multiple threads the solution is to have a global
counter which is bumped by fetch_and_add on every tx_add_range so that
we can recreate the order in which threads wrote stuff. Problem solved? Partially.
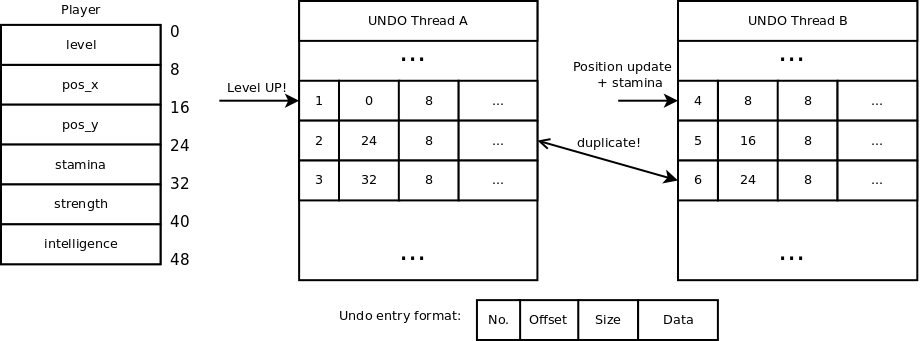 This is an example of the approach with numbering undo log entries. We have
thread A which level-ups a player, and so we need to update his level and
statistics (stamina and strength in this case) atomically. But thread B some
time later decided that player moved and by moving he also gained stamina
(because why not, example has to make sense). Since thread B does not have a
knowledge about what the thread A did, it adds another copy of the stamina stat
(this time with the data that was written by A). During recovery the sequence of
stores in recreated and the memory returns to pre-transaction state.
This is an example of the approach with numbering undo log entries. We have
thread A which level-ups a player, and so we need to update his level and
statistics (stamina and strength in this case) atomically. But thread B some
time later decided that player moved and by moving he also gained stamina
(because why not, example has to make sense). Since thread B does not have a
knowledge about what the thread A did, it adds another copy of the stamina stat
(this time with the data that was written by A). During recovery the sequence of
stores in recreated and the memory returns to pre-transaction state.
Our solution
There’s really no need to number the things on the list. That is only required if we expect the list to contain overlapping memory ranges. So let’s make our transactions to never contain duplicated memory. That requires each thread to know what other threads already added to the transaction and not add it the second time.
Every time a thread attempts to add something it is first required to
search the tree and add only the memory ranges that are not overlapping. This is
already done for pmemobj_tx_add_range* so that we never add duplicates into
the undo log (because that is just a waste of memory). Sadly our current tree
also uses a a lock. But this time the problem is easier because the added ranges
container is volatile and that means “compare and swap” is available. And we
don’t even need remove so no problem with requiring garbage collection
(or different tricks) for lock-free tree.
But that will be very difficult, and if we decide to roll our own it may prove nightmare to formally verify correctness. Right now I’m leaning towards a solution in which every thread has its own copy of the tree that would be kept in sync thanks to an insert-only, lock-free, singly-linked list to which all memory ranges (only offset and size) are appended.
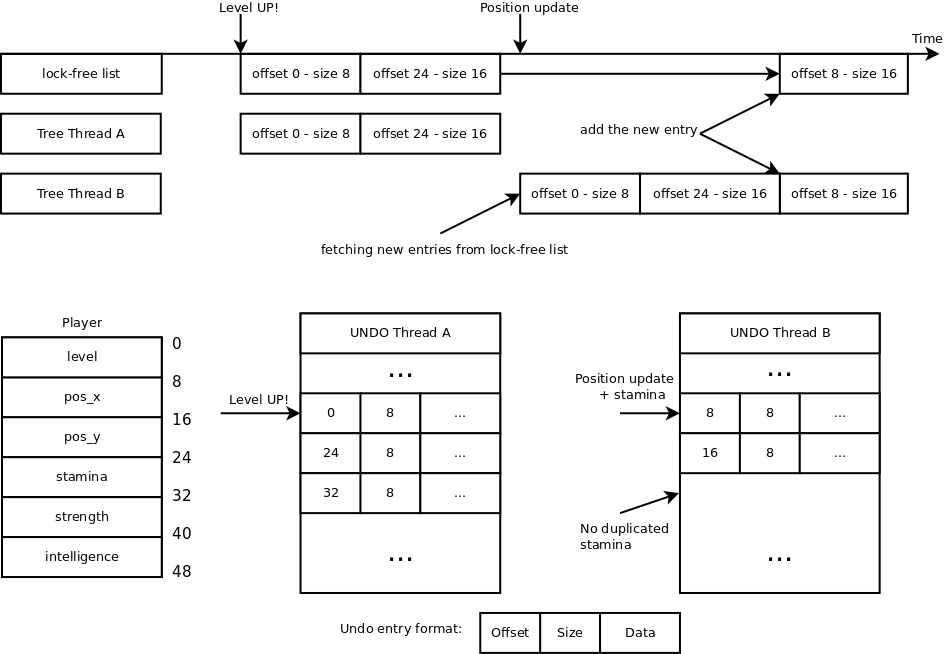
This is exactly the same example, but this time thread B fetches the contents of the global (per-transaction) list and avoids adding duplicates.
Don’t ask us when :) I’m afraid this is still a question of if and how.