Crawl, Walk, Run…
If you can’t fly then run, if you can’t run then walk, if you can’t walk then crawl, but whatever you do you have to keep moving forward.
Martin Luther King Jr.
This project, as well as the support for persistent memory in various operating systems, can be thought of as a crawl, walk, run approach. As byte-addressable persistence enters the market, modified system BIOS images and device drivers expose it to other modules in the kernel. Despite the byte-addressability, many of the initial usages are based on block storage device interfaces. But you have to start somewhere, so this is the crawl phase. The move beyond that, we need a software architecture for exposing persistent memory up the stack.
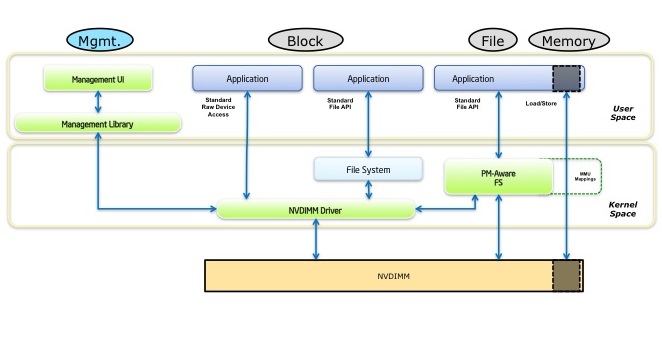
The picture above shows the walk phase of persistent memory support: exposing persistent memory up the stack so applications can leverage it. When the SNIA NVM Programming TWG (Technical Work Group) was discussing how persistent memory was exposed, there was a pervasive feeling in the group that the best approach would leverage existing mechanisms, like the file system naming and administrative model. So the recommendation published by the TWG matches the above diagram, and that’s the initial approach we see happening in the Linux community.
The idea is fairly straightforward. We want applications to have direct load/store access to persistent memory just as they do to traditional volatile memory. But since persistent memory is, well, persistent, applications are going to need to be able to express which blob of previously-stored data is desired when asking the OS for direct access to it. This is done using the well-understood file namespace. So walking through the path from hardware (at the bottom) to the application (at the top) in the above picture, we see a non-volatile DIMM (NVDIMM), which is one way of providing persistent memory to the platform, and it is managed by a driver in the OS labeled NVDIMM Driver in the picture. That driver provides access for manageability, shown on the left (for things like configuration changes and health monitoring). The driver may also provide the common block-based storage interfaces shown in the middle of the picture, so that existing file systems or applications that use block storage directly work without modification. But the more disruptive path (and the more interesting to this project) is the rightmost path where the application opens a file using a persistent memory aware file system and then memory-maps that file. This is done in Linux using the mmap(2) system call.
So this is the walk phase for persistent memory: when an application memory-maps a file from a persistent memory aware file system it gets direct access to the persistence (shown in the far right arrow in the above picture). Unlike the page-cache-cased memory mapping done by traditional file systems, the persistent memory aware file system literally provides the shortest possible path between an application and some storage! Once things are set up and initial page faults are taken, there’s no kernel code running at all when data is fetched from persistent memory – the application loads the data directly from the NVDIMM.
So what’s the run phase? Giving an application a large range of directly-mapped persistence is cool, but every application writer will then start the complex process of managing how data structures are laid out in that raw range of memory. That’s where libraries come in – to help application writers solve some of the more common problems like memory allocation or transactional updates. That will be the topic for an upcoming blog entry.